



Stable Diffusion(简称为SD)是AI艺术领域中的一项卓越技术。SD背后的技术学术上被称为Latent Diffusion,相关论文于2022年在著名的计算机科学会议CVPR上发布。
虽然我们只需要使用工具来绘画而不是深层次的学习机器知识,但还是在这里简单说一下SD的工作原理
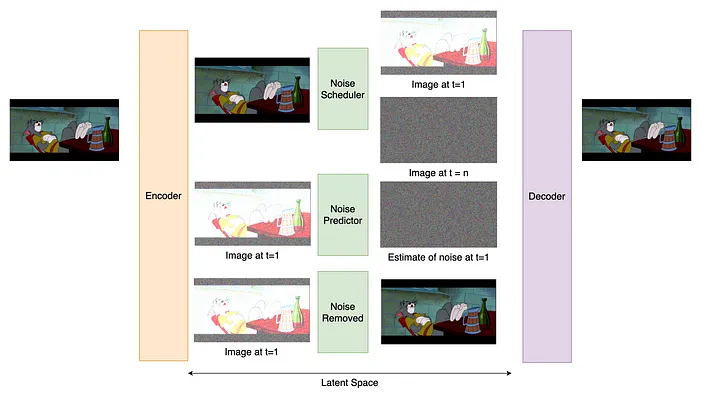
那么我们怎么使用SD绘画呢? 模型能够接受文本输入并生成相应的图像。该文本通常称为提示也就是提示词(Prompt),如下图所示,由 SD 模型生成。

但是在最初用户是需要用代码来与机器交互的,对小白非常不友好
2022 年 10 月,开源团体 AUTOMATIC1111 推出了一个名为“ stable-diffusion-webui ”的图形用户界面。该工具为普通用户提供了一个用户友好的解决方案来构建一个 UI 界面,从而能够使用 SD 模型创建图像。
通过此界面,用户可以利用各种 SD 模型功能,包括文本到图像、图像到图像、修复、外绘,甚至能够以指定的风格自定义训练全新模型。由于其开源特性、易用性和广泛的功能,SD WebUI 迅速崛起,成为 SD 模型套件中最引人注目和广泛使用的图形程序之一。
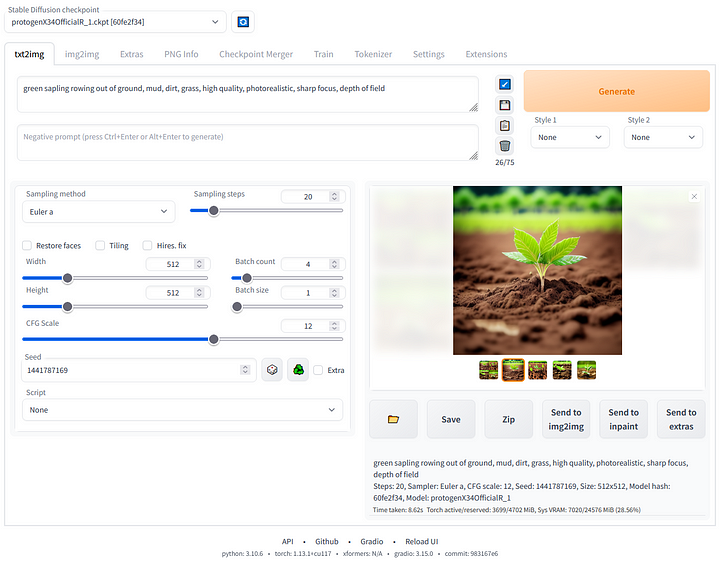
但是这个版本需要一系列环境配置,还是对小白不够友好
后来,国内B站的秋葉大佬,他发布的 SD 整合安装包解决了之前需要进行环境配置的问题,真正做到“一键安装”。
我目前用的就是这个整合包,安装过程顺利到自己都有点不敢相信。安装包下载链接在视频的简介里有说明,跟着 Up 的视频进行操作就与可以了。
或者还可以在线使用国外的云端站(需梯子) 立即使用
与 Midjourney 相比,Stable Diffusion(以下简称 SD)的优点有:
① 免费开源
Midjourney 需要开魔法使用,免费额度用完之后付费才能继续,最低 10 美元/月。而 SD 在 B 站上有大神整理好的整合安装包,不用魔法,免费下载一键安装。 安装到本地的 SD 随开随用,生成的图片只有自己能看到,保密性更强。
② 拥有强大的外接模型插件
由于开源属性,SD 有很多免费高质量的外接预训练模型(fine-tune)和插件,比如可以提取物体轮廓、人体姿势骨架、画面深度信息、进行语义分割的插件 Controlnet,使用它可以让我们在绘画过程中精准控制人物的动作姿势、手势和画面构图等细节;插件 Mov2Mov 可以将真人视频进行风格化转换;SD 还拥有 Inpainting 和 Outpainting 功能,可以对图像进行智能局部修改和外延,这些都是目前 Midjourney 无法做到的。
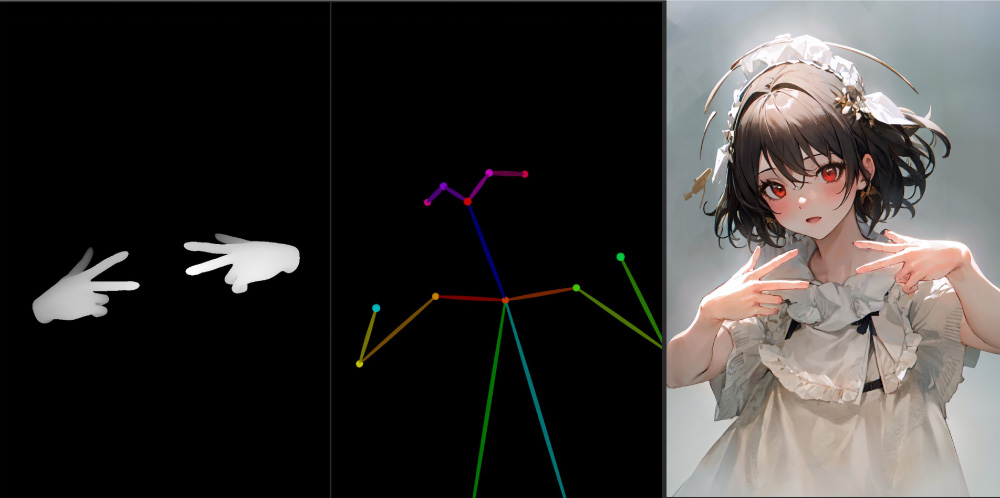
推特网友@Toyxyz3 通过分别渲染手部网格深度和开放姿势骨骼的方式,在 SD 内实现对人物手指和姿势的精准控制
③ 训练自己的模型
我们可以用 SD LORA 或者 Dreambooth 将自己喜欢的人物形象或者画风训练生成模型,打造自己的专属 AI 绘画工具,也有画师和设计师用自己的原创作品训练模型,之后有灵感了就之后用文字描述出来,让 SD 帮自己快速出各种概念草图。

利用吴仓石 、郑板桥、八大山人、任颐等大师作品+现代人物训练而成的水墨风 SD LORA 模型—— 墨心 Moxin
对电脑配置有要求
使用: 在本地用 SD 生成图像和训练模型都需要显卡做支撑,所以 SD 对电脑显卡有要求。最好是 Nvidia 的显卡(N 卡),显存至少 4G,不然图像的生成速度非常非常非常慢(不是夸张),也容易出现报错或系统崩溃。
训练: 如果你想自己训练模型,最好用高配置的台式机,显卡选 40 系列及以上,显存最低 12G,CPU 选 Intel i7 或者以上,内存越大越好。
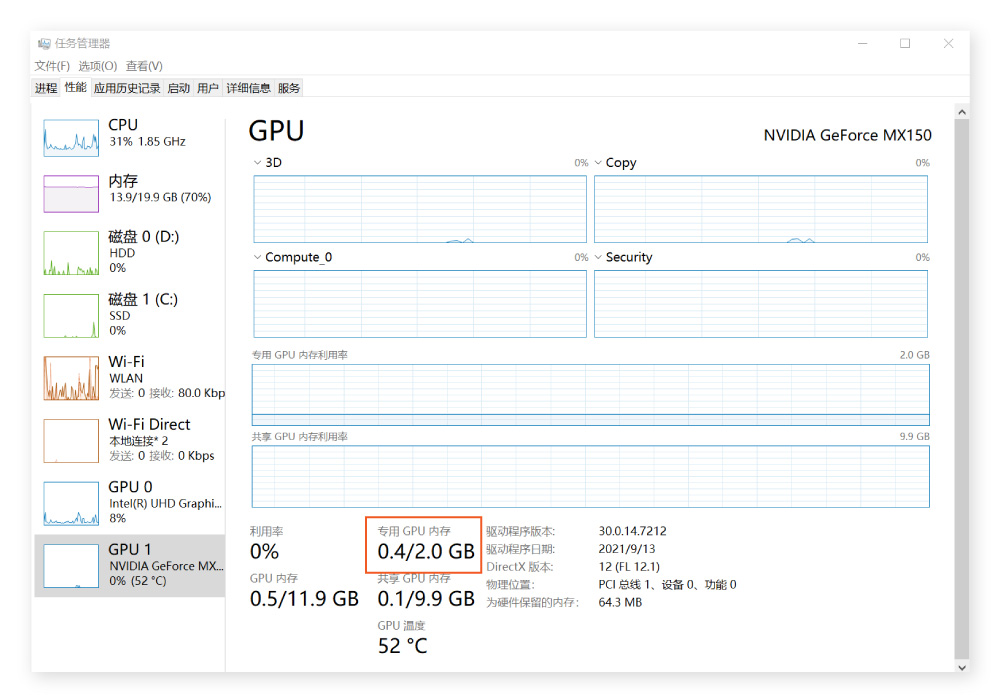
检查电脑显存的方法(windows):
鼠标放在工具栏,单击右键打开“任务管理器”,选择顶部的“性能”,进入后下拉查看 GPU 的部分,找到“专用 GPU 内存”,下面对应的数字就是电脑的显存。下图显示的电脑显存是 2G,生成一张最低配置的 512*512px 的图像需要 8 分钟,而 32G 显存的生成速度只需几秒,所以显存低的电脑不适合运行 Stable Diffusion。
因为 SD 所有文件都是安装在本地电脑上,而且生成不同的风格图像需要下载不同的模型,一个大模型至少 2G,假设你想要尝试 10 种风格,那 10 个大模型可能就要 30G 的空间。一般要求装 SD 的那个盘要有 100G 的剩余空间,最低不小于 40G,且最好不要安装在 C 盘。
