




作者使用 GPT-4o 生成
本周,Anthropic 发布了迄今为止我们所见过的前沿 AI 模型理解方面的最大飞跃。
对于前沿人工智能模型,我们遇到了一个奇怪的难题:我们知道它们有效,但我们不知道为什么,更糟糕的是,我们不知道它们是如何思考的。
然而,在过去几年里,人们对一个被称为“机械可解释性”的人工智能领域的兴趣与日俱增,它有一个明确的目标:在为时已晚之前,揭开可能在未来某一天给我们带来 AGI 的模型的神秘面纱。
现在,OpenAI 的主要竞争对手 Anthropic 发布了一项精彩且可能具有开创性的研究成果,该成果为我们提供了理解大型语言模型 (LLM) 的新方法,并揭示了我们如何尽快引导行为以防止不安全的做法。
然而令人悲伤的是,与科技领域中的任何事物一样,这一发现也有可怕的代价:增加了我们的社会变得“审查至上”和“一心一意”的可能性。
终极黑匣子
尽管我们对神经网络的学习方式有着很好的直觉,但我最近在博客中写到的一个主题是,模型发展成具有数十亿参数的架构仍然是一个完全的黑匣子,以至于我的公司的名字TheWhiteBox就是受这个问题的启发。
那么,首先,旨在纠正这一问题的机械可解释性领域是什么?
简单来说,该领域旨在识别网络所拥有的知识的关键模式以及它们与其参数的关系,以预测其行为。
您现在可能已经知道,像 ChatGPT 这样的神经网络是由位于以下“隐藏层”中的神经元(尽管适当的名称是“隐藏单元”)组成的:
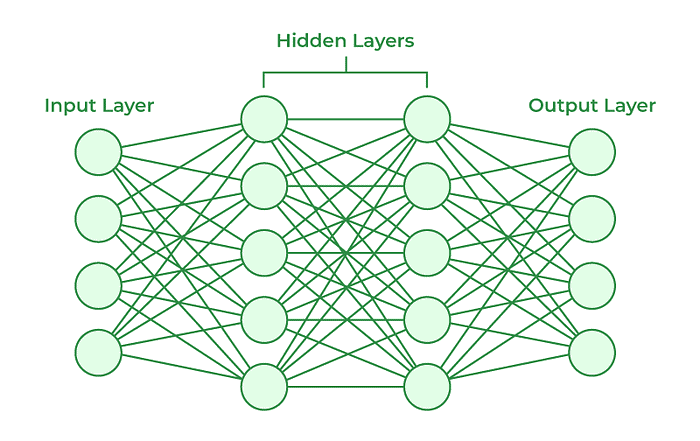
当受到提示时,这些神经元就会激发(或不激发),将这些元素结合起来有助于模型生成数据,例如缝纫学习指南或葛底斯堡战役的叙述。
简单来说,模型的输出取决于这些神经元的组合方式。然而,揭开这些组合的神秘面纱,看似无害,却是当今人工智能领域尚未解决的重大问题之一。
但为什么?
美丽的压缩动作
生成式人工智能模型本质上是数据压缩器。换句话说,它们被训练来压缩数据。
然而,众所周知,神经网络会应用叠加来捕捉比其拥有的神经元更多的事实。这种行为的原因是,它们被输入比模型大三到四个数量级(至少 100 倍)的训练数据,并负责学习和重新生成它。
因此,他们必须学会对数据进行压缩,以便在收到提示时能够“恢复”原始数据,尽管数据要小得多。
由于模型小得多,死记硬背不是一种选择,因为数据根本无法容纳在模型中。
事实上,这会将模型变成与原始训练数据大小相同的数据库,这是毫无意义的;我们想要的是一个仍然代表整个数据并且可以对其进行查询的小型生成模型。
因此,这个较小的模型被迫只吸收训练数据中的关键模式。然而,压缩不仅关乎效率,也关乎智能的开发。
压缩即智能
正如我多次提到的,这就是为什么世界各地的研究人员认为 LLM 是人工智能的——当前——圣杯;这些模型实现的令人印象深刻的压缩行为(只保留必要的部分,丢弃不相关的部分)清楚地表明了它们的智能(即使与人类相比它们相当愚蠢)。
但我所说的学习要领是什么意思呢?要理解为什么压缩是一种智能行为,我们可以以人类为参考。
例如,人类不需要死记硬背每个句子,而是学习语法和句法,也就是单词的书写方式和单词之间的联系,然后将这些知识推断成新的句子,而不需要死记硬背。
人类知道“我吃香蕉”不是一个正确的句子,而不必记住这三个单词的每个连贯方式。
这也正是 LLM 所做的,但我们无法真正解释为什么或如何,这就是机械可解释性的重点。
但我为什么要告诉你这些呢?
很简单。压缩是这些模型所期望的特性,但它也意味着一个难以避免的事实:
它们最小的信息压缩和存储单元——神经元,是多语义的。
残酷的事实
如前所述,神经网络应用叠加来积累比其拥有的神经元更多的知识数据点。
因此,为了实现这一点,每个神经元都要对各种语义上不相关的主题有深入的了解。例如,当模型生成莎士比亚的诗歌和写关于热带青蛙的文章时,同一个神经元可能会被激发。
亲爱的读者,这是一个问题。
如果神经元是单义的,那么揭示 LLM 的知识以及它如何引出这些知识将是轻而易举的事。
然而,由于它们是多义的,因此单独分析每个神经元来揭示“它们知道什么”,从而映射整个网络的知识,这完全不可能。
幸运的是,2023 年 10 月,Anthropic 有了重大发现:虽然神经元毫无疑问是多义的,但它们的某些组合是单义的。
通俗地说,虽然仅根据一个神经元的行为无法预测模型的结果,但每当一组神经元一起激发时,结果总是相同的。
换句话说,当模型生成特定主题的文本时,相同的神经元会一起激发。这可以在下面的小图中看到,其中两个隐藏神经元(两个神经元都会激发)的特定组合迫使模型输出莎士比亚诗句。
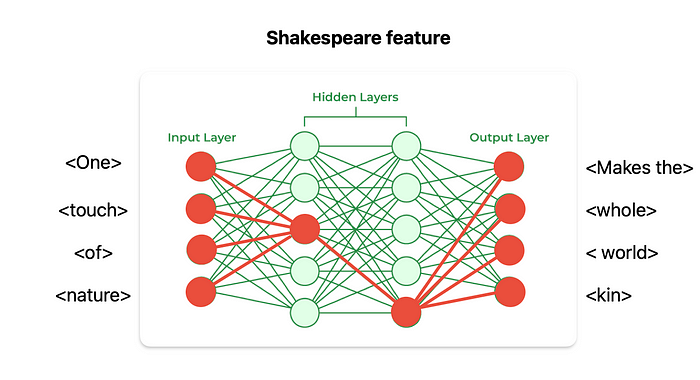
作者创建
然而问题在于这一发现是有限的,因为他们研究的神经网络非常非常小,这意味着单义神经元组合是一个有希望的领域,但不是现实。
然而,经过 Anthropic 的出色新研究,它现在已成为现实。
希望十四行诗
最近,发现单义神经元组合的同一团队发表了一篇论文,他们将同样的原理应用于他们的中端生产前沿模型Claude 3 Sonnet,该模型目前是世界第九好的法学硕士。
但他们具体做了什么呢?
解读前沿人工智能模型
他们分析了模型的激活并训练了一个并行模型,将它们转化为可解释的特征。
通俗地说,他们训练了一个模型,观察 Sonnet 中的神经元如何放电,并预测这些神经元的组合代表哪些关键的抽象特征,从而创建研究人员可以解读的“特征图”。换句话说,他们找到了世界概念和某些神经元组合之间的“地图”。
例如,他们发现了旧金山“金门大桥”特有的特色:

重要的是,这些特征是多模式的(对与该纪念碑相关的文字和图像都有反应)和多语言的(对其他语言中的相同概念都有反应)。
此外,他们还发现了有关名人、纪念碑、艺术等的特征。
但是他们是如何做到的呢?
重建促进学习
为了实现这一目标,他们训练了一个稀疏自动编码器(SAE),该模型将激活转化为现实生活中的特征,然后尝试重建激活。
SAE 有两个组成部分:
- 编码器,从模型中获取激活值,并将线性变换应用到更高维空间中,以将其转换为特征。通俗地说,该模型可以找到诸如“如果神经元以某种方式激发,它们通常会指代勒布朗·詹姆斯”之类的模式。
- 解码器获取这些特征并应用另一个线性变换将特征返回到原始激活。
换句话说,他们训练了一个模型,该模型可以将神经元激活“解剖”为更细粒度的数据(可解释的特征),但也可以重建原始数据(回到原始激活)。
重建部分不是“仅仅因为”而完成的。
通过强制模型重建原始数据,它们必须了解数据最初的分布方式,这相当于真正理解它。
如下所示,对于“金门”、“大门”或“大桥”等词,模型的神经元会朝着“金门”特征的方向激活。这反过来意味着这些特征被添加为相关信息以执行下一个词预测,从而导致模型输出“旧金山”作为这座纪念碑所在的美国城市。
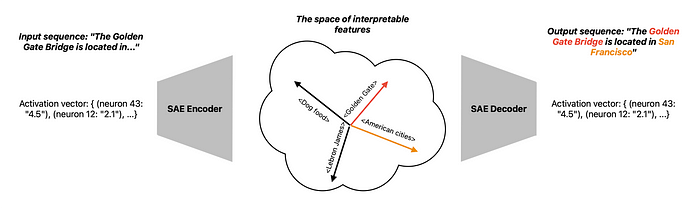
作者创建
长话短说,该过程如下:
- 他们训练了一个 SAE,它采用 LLM 的激活并将其转化为现实生活中的特征。
- 他们分析了序列中每个单词的神经元激活情况。例如,他们发现每当一组神经元激活时,该单词总是与金门大桥相关,因此能够将该特征识别为“金门大桥”。
- 因此,他们找到了影响序列中每个单词生成的一组特征,使得完全不透明的神经元世界变得可以解释。
但是,这些特征可能有数千个,对吗?
“哈士奇”这个词可以直接与许多不同的特征相关:<狗>、<哺乳动物>、<毛茸茸>、<动物>、<家养>等等,这使得找到解释每个单词的关键特征的过程成为一场噩梦。
因此,他们强制 SAE 变得稀疏,这意味着少数特征应该只代表序列中的每个单词。这样,他们就可以精确地指出这些神经元“指称”的确切现实概念。
技术见解:为了加强稀疏性,他们在 SAE 的目标损失函数中添加了一个惩罚项。这个惩罚项计算了解码器矩阵的行列式,这意味着它的值越大,惩罚就越大。这自然会促使模型分配一个有效但稀疏的矩阵。
通过这样做,他们还获得了另一个好处:解码器矩阵,即获取特征并将其转换回激活的矩阵,代表了模型的特征空间。通俗地说,解码器矩阵的列是可以“解释”任何给定单词的不同可能特征。
因此,它充当“特征查找”的角色,因为模型只需要查看哪些列参与了重建,就可以知道哪些特征可以解释这些特定的激活。例如,如果单词是“Golden Gate”,则解码器激活中的其中一列将是指代“Golden Gate”特征的列。
但为什么这一切都很重要?
很简单,因为通过了解神经元如何组合来生成与特定主题相关的数据,我们可以预测其行为……或者,至关重要的是,引导它。
为了证明这一点,再次使用金门大桥的例子,他们限制了特定的组合(迫使这些特定的神经元更强烈地激活),这迫使模型实际上认为它是金门大桥:
当然,这只是一个有趣而又无关紧要的回应,但关键是,他们证明了我们确实可以随心所欲地“限制”或“压制”特定的话题。
有趣的是,但这一切对行业来说意味着什么,好还是坏?
可预测但可审查?
毫不奇怪,研究人员发现了许多不良特征(撒谎、欺骗、权力追求行为,甚至是暴力反应)。
减少暴力
利用这一发现,我们最终可以“调低”甚至禁止这种神经元组合,这样无论用户如何坚持,模型都不会生成这种数据。
考虑到如今越狱的难度,这一点至关重要。
例如,虽然模型可能会拒绝英语中的有害请求,但它可能会遵守尚未“对齐”的语言。通俗地说,在训练阶段,我们向模型解释“每当他们要求你制造炸弹时,不要回答”之类的事情,主要是用英语进行的,而不是用不太知名的语言。
然而,由于特征是多语言的,禁止某些神经元组合将导致模型独立于语言而拒绝有害提示。
话虽如此,这些预防措施只有在攻击者无法访问实际模型的情况下才会起作用。对模型进行简单的微调就可以完全修改它,并轻松破坏对齐护栏。
而且,正如Nanda 等人最近的研究证明的那样,我们甚至不需要对模型进行微调,只需消除“安全功能”即可让模型自动失控,从而使情况变得更糟。
尽管如此,这一突破极其重要,因为在更未来的事件中,我们必须处理超人模型,这些模型在各个方面都比我们优秀,了解它们如何处理数据不仅可以帮助我们发现新的突破,还可以帮助我们学习如何控制和防止它们失控。
然而,正如当今人工智能领域的任何发现一样,它也有其不利的一面。
走向脑白质切除社会
想象一个世界,每个人都使用由营利性公司授予的相同的法学硕士学位。
在这种情况下,是什么阻止这些公司利用这些能力来审查某些思维方式、操纵或欺骗社会,以有利于这些公司或其背后政府的利益的方式看待世界?
我们必须承认,尽管法学硕士学位将为社会创造巨大的价值,但将其作为获取知识的唯一门户(他们显然将自己定位为这一门户)可能会极为有害。
由于每个人都陷入相同的思维方式,我们失去了开放思想的能力。
这听起来有些夸张,但人工智能算法已经在以各种方式操纵社会。如果某个社交网络只向你孩子的推送有关某个种族或宗教的有害内容,那么我们的孩子长大后怎么会厌恶我们人工智能控制的推送中没有包含的内容呢?
我并不谴责企业在推动行业发展方面发挥的重要作用;我相信他们的产品将为社会创造巨大的价值。
