



苹果到底在做什么?
这个问题可能是华尔街最近热议的话题。微软乘着 OpenAI 的浪潮,谷歌在突破法学硕士的界限的同时,却表现得非常笨拙——而且带有种族歧视的色彩,而英伟达在短短两个月内就将特斯拉的股票价值提升到了其估值的水平,而苹果却不见了踪影。
然而,它们确实在移动,尽管方式并非大多数人所预料的那样。
今天我们来介绍一下他们最新发布的MGIE,它给了我们很多关于他们的 AI 战略的提示,同时也为当今最热门的 AI 工作敲响了丧钟。
第二名总是第一名
多年来,苹果已经掌握了让别人先行并最终夺得一切的技巧。
- 他们在智能手机市场也这么做了
- 他们在耳机市场上也这么做
- 他们可能会在耳机市场上这么做(尽管结果尚不清楚)
人工智能也不会有什么不同。
从 Siri 到 Ajax
苹果从来都不是人工智能领域的领先者。
那最初是谷歌,word2vec 和 Transformer 等当今人工智能的开创者就是在这里诞生的。
然而,令人惊讶的是,过去几年他们在人工智能相关的领域取得的进展却非常少。
事实上,如果我们考虑到微软在其产品上大规模部署了 Copilot 等工具,而苹果仍然依赖 Siri,那么这种比较实际上是令人尴尬的。
然而,由于开放市场总是试图为未来定价,苹果仍然能够乘上人工智能浪潮,不是因为他们已经实现了什么,而是因为他们对未来将实现什么的承诺。
当然,微软或谷歌等公司的命运更多地取决于其人工智能承诺的实现,但苹果再也不能假装其去年估值的部分(如果不是全部)增长从根本上是由人工智能炒作推动的。
例如,苹果 iPhone 的销量在过去三年里基本停滞不前:
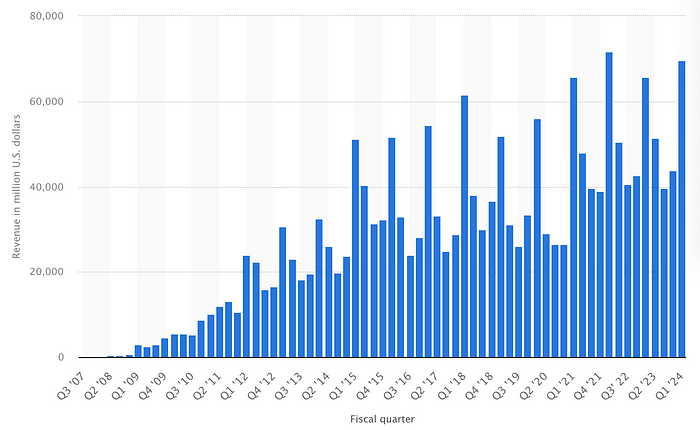
来源:Statista
考虑到 iPhone 占据了其 52% 的收入份额,这不是什么好消息。事实上,其收入趋势几乎与 iPhone 相同。
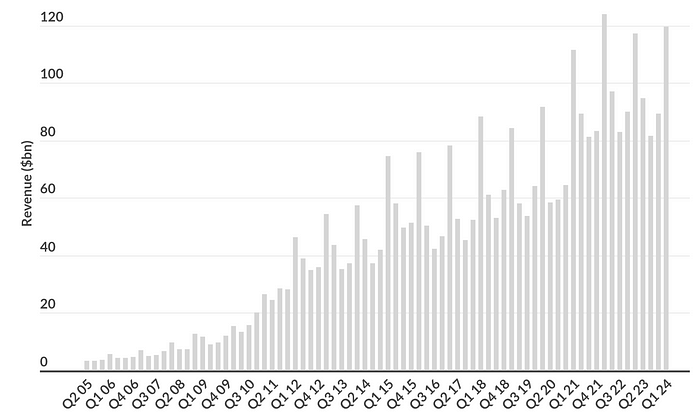
尽管如此,苹果的股价还是跟随“七巨头”其他股票的上涨而上涨。
过去几个月,有传言称苹果正在大力投资自己的法学硕士(代号为“Ajax”),并且还暗示他们正大力依靠Flash LLM的研究来发展消费端人工智能,这使得这些模型可以存储在 Flash 上,而不是完全存储在内存(RAM 或 HBM)中,从而可以在智能手机上部署更大的模型。
最近,他们宣布放弃打造“苹果汽车”的梦想,将全力专注于生成式人工智能。
不管怎样,苹果需要尽快开始提供人工智能。
这将带我们走进MGIE。
增强图像编辑
简单来说,Apple 提出了一个名为MLLM-Guided Image Editing (MGIE)的框架,用于改进图像编辑,通过结合多模态大型语言模型 (MLLM) 和扩散模型,让您可以有效地编辑图像:

为此,他们组装了一个相当标准的 MLLM+Diffusion 模型架构。然而,他们添加了两个变化,使这个架构变得特别有趣。
增强表现力
对于编辑图像等复杂主题,尤其是如果唯一的方式是通过文本进行编辑,用户通常无法很好地描述他们想要什么,这使得模型的执行过程变得更加困难。
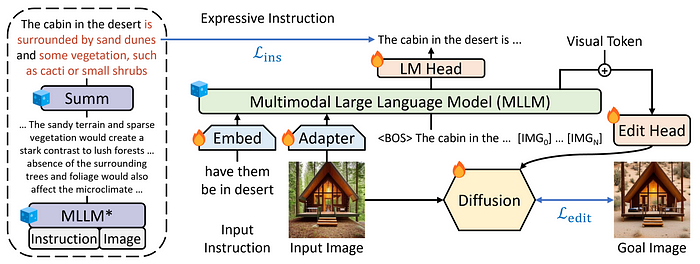
来源:Apple
在这里,Apple 建议通过两种方式训练 MLLM 来学习增强用户提示:
- 让它们更少冗长,更切中要点
- 增强描述的表达力,使不那么模糊的解释变得更加丰富
为了实现这一点,他们添加了损失优化,使用交叉熵损失将他们的 MLLM 的输出与“文本摘要器”(如左图所示)的输出进行比较。
交叉熵损失本质上比较了两个模型的概率分布,并迫使模型学习以类似于老师的方式输出响应(在本例中为文本摘要器)。
但是,这是什么意思?
当我们说 LLM “预测序列中的下一个单词”时,我们真正的意思是该模型为您提供了给定文本输入的“下一个单词的概率分布” 。
换句话说,该模型输出它可以提供的可能单词的完整列表,并按成为合适的下一个单词的概率进行排序。
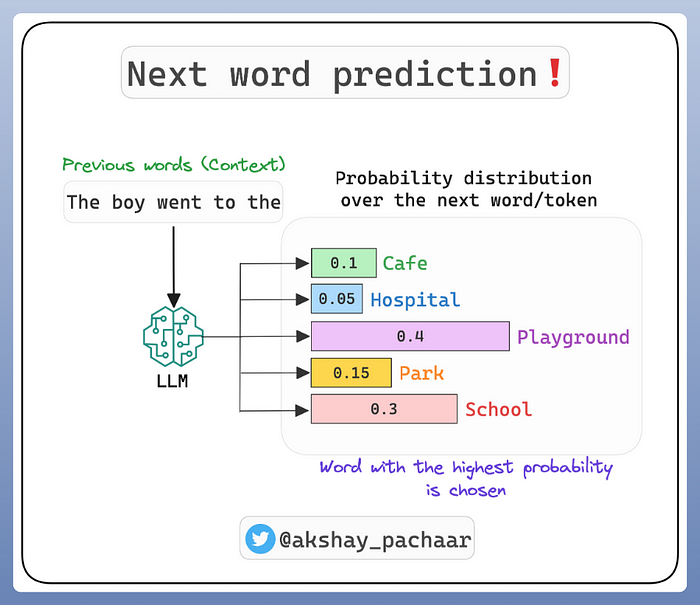
然后,模型从该分布中抽取一个单词(通常是分配概率最高的单词或前 k 个单词之一,具体取决于模型当时的创造力),这就是您在聊天界面中实际看到的内容。
然而,在这种情况下,这里的 MLLM 不仅仅是根据下一个单词的充分性进行评估,而且还根据它的概率分布与文本摘要器的概率分布的相似性进行评估。
换句话说,模型分配给每个可能单词的不同概率必须与文本摘要器给出的概率相似。实际上,您正在诱导模型以类似于其老师的方式对语言进行建模。
此外,他们还增强了 MLLM 和扩散模型的交流方式,他们将其描述为“潜在的视觉想象”。
隐藏的视觉想象力
与卡内基梅隆大学的研究人员对GILL所做的工作类似,他们学习了针对扩散模型的特定条件系统。
扩散模型是采用用户需求的文本描述并生成与用户请求在语义上相关的图像(或视频)的模型。
因此,它们是条件图像生成模型,从某种意义上说,它们需要一个条件来知道要生成什么。
在标准方法中,您只需要一个扩散模型作为唯一的架构组件(与独立的 Dall-E 一样),但在这里 Apple 建议使用 MLLM 作为用户和扩散模型之间的代理,以便 MLLM 增强用户的提示。
之所以如此,是因为研究人员认为:
- MLLM 确实能对来自图像和文本的知识进行编码
- MLLM 可用于增强响应生成(如我们在上一节中看到的那样)
基于前者,他们形成了 MGIE 架构,其中扩散模型接收由 MLLM 提供的增强条件,而不是用户给出的传统纯文本描述。
为了进一步理解我的意思,GILL 团队提供的图表更具解释性:
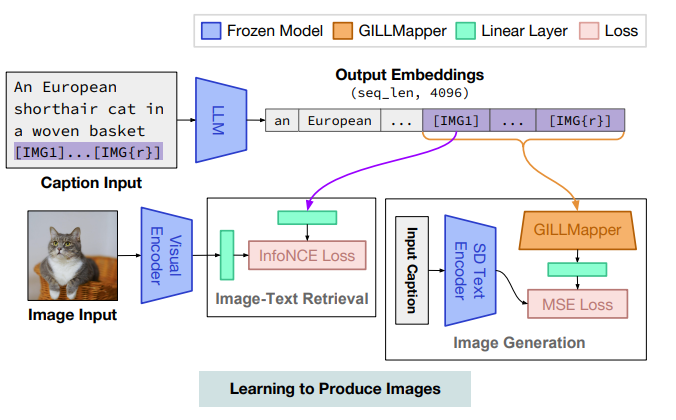
- 当收到用户的提示和需要编辑的图像时,MLLM 会生成由文本和图像标记组成的响应。
由于 MLLM 已经对两种输入类型进行了训练,它们“理解”‘猫’的概念与图像或文本描述相同。
- 为了生成新图像,我们不是像传统方法那样向其发送文本描述,而是使用编辑模型(相当于上面显示的 GILL 中使用的“GILL Mapper”)来转换这些标记。
- 该编辑模型从 MLLM 中获取预测的图像标记,并将它们转换为一组新的标记,然后扩散模型就可以处理这些标记。
- 而且,这些标记比纯文本标记更具表现力和丰富性,这意味着扩散模型(在本例中为稳定扩散)对需要在原始图像上编辑什么有更清晰的认识。
技术说明:在实际预测图像标记(在上图中表示为 [IMG])之前,编辑模型还将 MLLM 最后一层的输出作为输入。
这些潜在的表示提供了更丰富的视觉理解,从而帮助模型更好地理解需要编辑的内容。
但对我而言,MGIE 远不止眼前所见那么简单。
苹果论文的主要结论之一是,它无可否认地证明了法学硕士 (LLM) 正在成为培养基于人工智能的快速工程师的一个非常可行的选择,这本身就是一个令人担忧的话题。
及时工程是指优化我们与 LLM 的沟通方式。
及时工程被认为是人类持续训练和使用人工智能模型的主要原因之一。
但随着 MGIE 或Google Deepmind 的 PromptBreeder等案例的出现,人工智能最终在提示其他人工智能模型方面变得比我们更好的可能性比以往任何时候都高。
不过,MGIE虽然不错,但它的意义并不在于技术,而在于苹果所含蓄预示的东西。
消费者AI 2.0
随着每一篇与苹果品牌签约的研究论文,苹果的AI战略越来越明显。
他们似乎不愿意与微软/OpenAI、谷歌/Deepmind 等公司在前沿领域竞争,而是更专注于利用这些进步来增强他们的消费产品。
尽管我并不怀疑苹果正在大力投资构建前沿人工智能模型,但他们今天的战略似乎更加“脚踏实地”,专注于确保他们的消费产品保持竞争力并与当前趋势保持同步。
因此,如果苹果不在未来几个月内发布强大的图像编辑功能(或者可能瞄准下一次重大 iOS 更新),利用其广泛的产品生态系统和可能被认为是历史上最有价值的品牌,将自己打造成“消费者 AI 领导者”,那对我来说将是非常震惊的。
另一方面,他们的行动非常缓慢,时机总是很重要。如果他们行动太迟缓,苹果可能会被视为“不适合”玩人工智能游戏,这可能会导致其估值和销售额大幅下降。
