




介绍
一年来,OpenAI 一直处于 AI 技术的前沿。特别是在数据提取方面,当不涉及推理时,GPT-3.5 是完美的匹配。有了 GPT4 愿景,很多大门都敞开了,但仍然受到GPT4 庞大规模和可怜的速率限制的限制。
Claude 3 面世了,它不仅提供了更强大的模型 Opus,还提供了一组能够进行惊人数据/文档提取的其他模型。这绝非偶然,因为大多数训练数据都由文档结构和内容组成,正如您在演示中看到的那样,它基本上是上一篇关于该主题的文章的更高级版本。
您可以在 Github 上检查此代码库,以前的同一个 repo 已使用此内容进行更新。
GPT-4 与 Claude 3
克劳德之前 3
即使现在有了 GPT4 的视觉,最先进的技术也总是通过 OCR 和 LLM 来读取。视觉模型往往更慢、更昂贵。所以你总是会有这样的分布:
提取请求的成本分配
在之前关于这个主题的文章中,我使用了开源解决方案(Tesseract+Mistral),但还有更成熟的解决方案。使用 Claude,您可以绕过此方法,因为您有Haiku 模型。
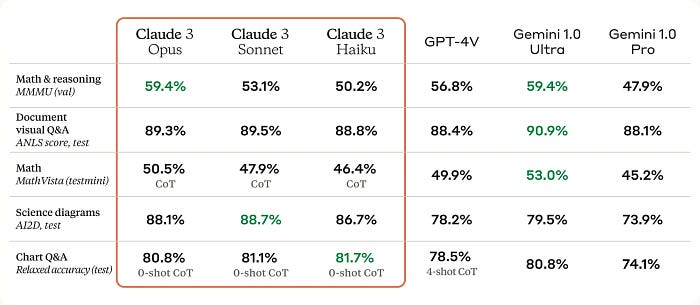
https://www.anthropic.com/news/claude-3-family
Haiku 足以用于扫描文档。对于分类等其他任务,应该使用 Sonnet,效果非常好。没有必要立即转向 Opus,因为它的价格要高得多,而且不太容易获得(截至本文撰写时,AWS 中尚未提供)。
成本和速度比较
Claude 3 和 GPT4之间最大的区别在于输入端的 token 消耗,在 token 数量上相差一个数量级,但在价格上相差无几。
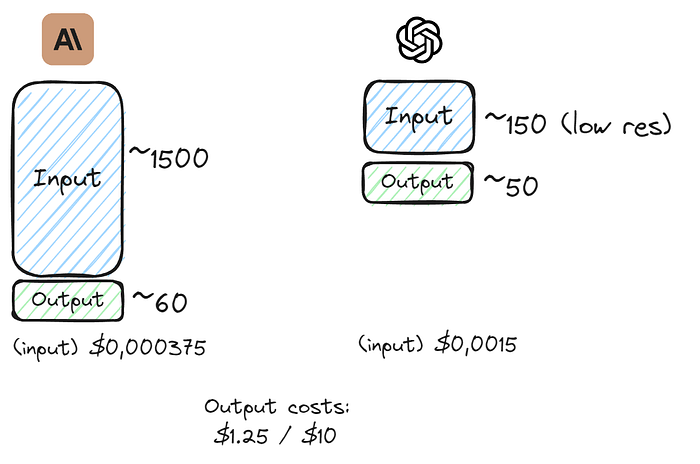
我们可以看到,即使 Claude 端没有任何图像处理,它也便宜得多。有关图像处理的更多信息,请参见下文。
就速度而言,两者并无二致,而 Claude 以超过 50% 的明显进步获胜,而且同样没有经过任何操纵。
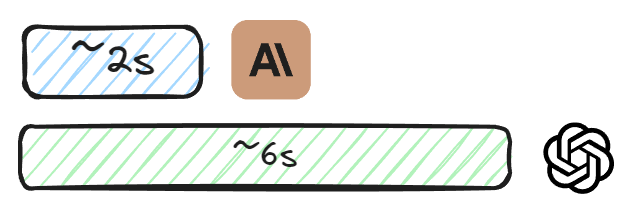
价格会有所变化,但您始终可以检查 Haiku 和 Sonnet 之间的区别,但就视觉而言,它们在指标方面相似,因此您应该始终使用 Haiku,然后单独处理数据。
数据提取
现在让我们看一下实际的代码。我将扩展上面提到的GitHub repo,该 repo 因上一篇文章而获得了一些关注。
让我们定义将在以下用例中使用的AnthropicsApiService :
class AnthropicsApiService:
def __init__(self, api_key: str):
self.client = anthropic.Anthropic(api_key=api_key)
def send_message(self, initial_request: AnthropicsApiRequest) -> str:
final_response = None
request = initial_request
sb = []
while True:
message = self.client.messages.create(
model=request.model,
max_tokens=request.max_tokens,
temperature=0,
system=request.system,
messages=[msg.__dict__ for msg in request.messages]
)
if hasattr(message, 'error') and message.error and message.error['type'] == "overloaded_error":
continue
if hasattr(message, 'error') and message.error:
raise Exception(f"API request failed: {message.error['message']}")
final_response = message
content = self.remove_json_format(final_response.content[0].text)
if final_response.stop_reason != "end_turn":
content = self.removeLastElement(content)
sb.append(content)
# big file logic
if final_response.stop_reason != "end_turn":
last_message = content
if last_message:
request.messages.append(Message(role="assistant", content=last_message))
request.messages.append(Message(role="user", content="##continue JSON"))
if final_response.stop_reason == "end_turn":
break
return "".join(sb)
def send_image_message(self, initial_request: AnthropicsApiRequest, base64_image: str) -> str:
final_response = None
request = initial_request
sb = []
while True:
start_time = time.time()
message = self.client.messages.create(
model=request.model,
max_tokens=request.max_tokens,
temperature=0,
system=request.system,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
},
{
"type": "text",
"text": request.messages[0].content
}
]
}
]
)
response_time = time.time() - start_time
print(f"Response time: {response_time} seconds")
if hasattr(message, 'error') and message.error and message.error['type'] == "overloaded_error":
continue
if hasattr(message, 'error') and message.error:
raise Exception(f"API request failed: {message.error['message']}")
final_response = message
content = self.remove_json_format(final_response.content[0].text)
if final_response.stop_reason != "end_turn":
content = self.removeLastElement(content)
sb.append(content)
if final_response.stop_reason == "end_turn":
break
return "".join(sb)
文档提取
如上所述,此提取应始终使用 Haiku。请求只是构建提示并将图像内容加载为字符串。
@app.post("/extractClaude")
async def process_image_with_claude(file: UploadFile = File(...), extraction_contract: str = Form(...)):
# Create a temporary file and save the uploaded file to it
temp_file = tempfile.NamedTemporaryFile(delete=False)
shutil.copyfileobj(file.file, temp_file)
file_path = temp_file.name
# Convert the file to base64
with open(file_path, "rb") as f:
base64_encoded_image = base64.b64encode(f.read()).decode()
# Create an instance of AnthropicsApiService
api_service = AnthropicsApiService(API_KEY_ANTROPIC)
# Prepare the prompt
prompt = f"###Contract\n{extraction_contract}"
# Build the messages
messages = [Message(role="user", content=prompt)]
# Set the model
model = "claude-3-haiku-20240307"
# Create an instance of AnthropicsApiRequest
api_request = AnthropicsApiRequest(
model=model,
max_tokens=2000,
messages=messages,
system="You are a server API that receives an image and returns a JSON object with the content of the contract supplied"
)
# Send the data to the Anthropics service and get the response
response = api_service.send_image_message(api_request, base64_encoded_image)
# Return the response
return {"Content": response}
处理图像以减少 token
OpenAI 在 API 上默认有一个“细节”字段,可以从“高”更改为“低”和“自动”,以节省消耗。但在这里我们必须自己做。您应该管理图像的分辨率,以确保您没有使用不必要的令牌,因为图像在质量方面“太好了”。
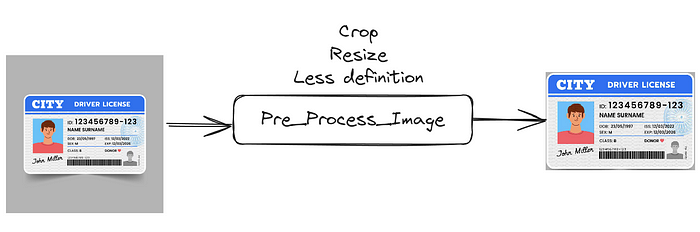
Python 中的 Pre_Process_Image
这是管理令牌使用情况的好方法,只需确保您的方法不会损害结果即可。以下是可以用作起点的代码。根据我的测试,大多数图像在质量降低 50% 的情况下仍能正常工作。
Excel 提取
这是 GPT-4 遇到的一个经典问题。当你使用一个结构不太好的文件时,它往往会失败。使用 Claude 3 你甚至不需要 Opus,Sonnet 就能以 40% 的成本完成工作。此外,Claude 已经通过了“大海捞针”测试,这使得该工具在没有推理技能的情况下更加出色。
假设您有一个非结构化的 Excel 文件,并且想要根据合同提取数据。请看以下 Excel:
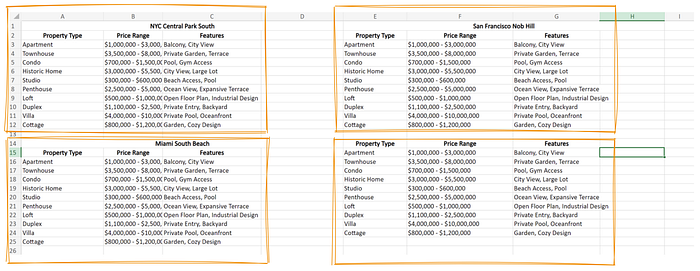
真实示例模拟
合同将是这样的,伪 YAML:
realEstate: Array, contains all the elements state: string, state code district: string propertyType: string priceRange: integer features: string[]
代码如下:
@app.post("/extractExcel")
async def process_excel_file(file: UploadFile = File(...), extraction_contract: str = Form(...)):
df = pd.read_excel(io.BytesIO(await file.read()))
# Convert the DataFrame to a string
data = df.to_string(index=False)
# Create an instance of AnthropicsApiService
api_service = AnthropicsApiService(API_KEY_ANTROPIC)
# Prepare the prompt
prompt = f"##Content\r\n{data}\r\n##contract\r\n{extraction_contract}\r\n\n##Result in JSON"
# Build the messages
messages = [Message(role="user", content=prompt)]
# Set the model
model = "claude-3-haiku-20240307"
# Create an instance of AnthropicsApiRequest
api_request = AnthropicsApiRequest(
model=model,
max_tokens=4000,
messages=messages,
system="You are a server API that receives an image and returns a JSON object with the content of the contract supplied"
)
# Send the data to the Anthropics service and get the response
response = api_service.send_message(api_request)
# Return the response
return {"Content": response}
因此,在此代码中,我们没有考虑上下文大小,因为这不是主要问题(但对于极端示例来说可能是主要问题,因此请记住这一点)。我们从电子表格中获取内容,将数据除以每张表,然后请求我们指定的合同。以下是请求上下文的示例:

响应为 JSON。映射大内容
这是每个模型中常见的问题,因为最大 token 响应往往总是在 4000 个 token 左右。经过多次重试后,我建议使用“删除最后一个元素”技术,如下所示:
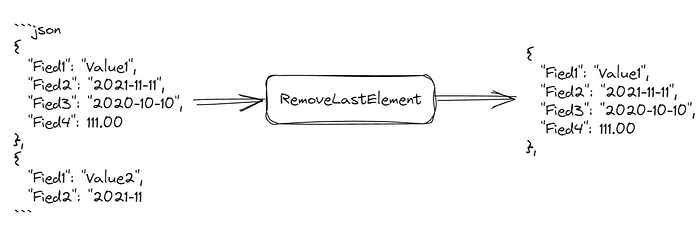
您还应该注意JSON格式,并确保捕获每个用例,然后将其添加到响应中。以下是代码:
@staticmethod
def removeLastElement(json_string: str) -> str:
try:
json.loads(json_string)
return json_string
except json.JSONDecodeError:
pass
last_index = json_string.rfind("},")
if last_index == -1:
return json_string
trimmed_string = json_string[:last_index + 1]
trimmed_string += ","
return trimmed_string
结论
Claude 做了一件很棒的事情,在市场上发现了一个尚未被探索的利基市场。在第 3 版之前,我告诉过几个客户,我不会发布某些类型的功能,因为 GPT4 在速度、成本和可扩展性(代币可用性)方面还不够。现在,在提取方面一切皆有可能,我可以告诉你,我的付出是痛苦的!现在我迫不及待地想把一切都切换到 Claude 3!
