文本转语音 (TTS)
您是否正在开发需要大声朗读文本的 AI 或机器学习项目?如果是这样,您可能需要考虑使用免费的开源文本转语音引擎。本文将解释这些引擎的工作原理,并推荐一些可用的最佳开源选项。
但首先,什么是 TTS?
首先,让我们来分析一下什么是文本转语音引擎。这是一个可以将书面文本转换为口语的计算机程序。这些引擎使用自然语言处理来理解文本,然后将其转换为听起来像人说话的语音。文本转语音引擎用于您可能已经使用的许多事物,例如智能手机助手、GPS 导航和帮助残障人士的工具。
开源文本转语音引擎
开源 TTS 引擎提供了一种将文本转换为语音的强大方法,使其成为构建可访问工具、自动语音系统和虚拟助手的理想选择。这些引擎由开发人员社区创建和共享,任何人都可以自由使用、调整和分发它们。以下是 TTS 引擎的列表:
1. MaryTTS
MaryTTS 的模块化设计使其适应性出众。这意味着您可以构建自定义的文本转语音系统,甚至可以使用录音创建新的声音。以下是其主要组件的细分:
- 标记语言解析器:该组件解读文本中嵌入的特殊代码,为系统提供指令。
- 处理器:获取解析后的文本并准备进行转换,例如将其转换为语音指令。
- 合成器:最后一步!该组件生成实际的语音输出,并添加音调和重音等自然音质。
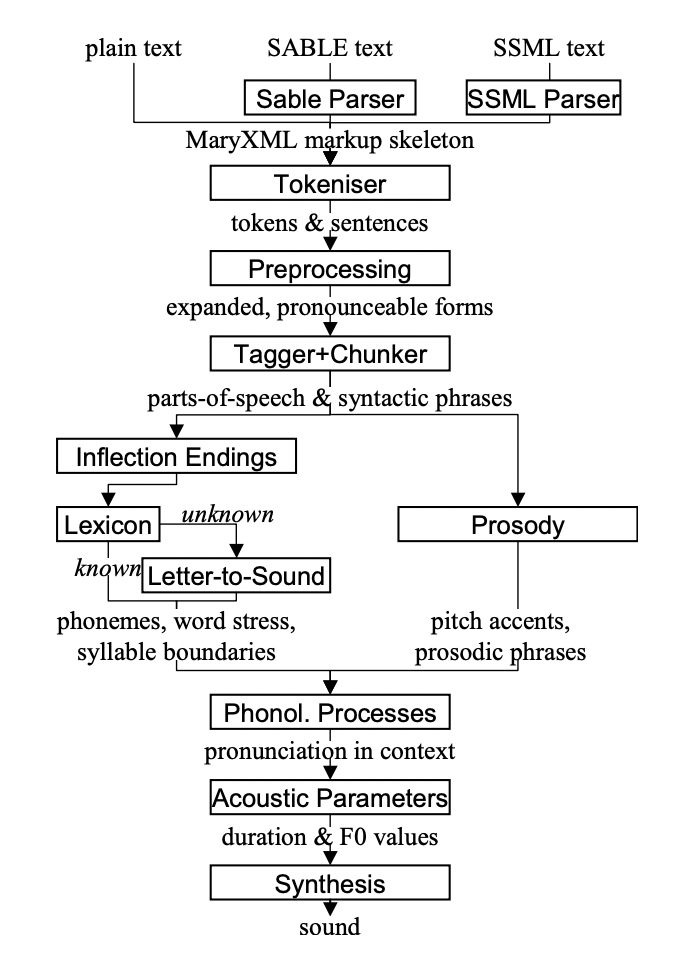
MaryTTS。GitHub
2. eSpeak:简单而多功能的文本转语音引擎
如果您正在寻找一种简单且语言友好的选项,eSpeak 是一个不错的开源选择。该软件擅长以多种语言提供清晰的语音,同时保持其体积小巧。另一个好处是它与各种操作系统兼容,如 Windows、Linux、macOS 甚至 Android。
以下是 eSpeak 优缺点的简要概述:
优点:
- 方便使用的
- 支持多种语言和声音
缺点:
- 缺乏高级功能和自定义选项
- 用 C 语言编写(高级使用可能需要编程知识)

eSpeak。链接
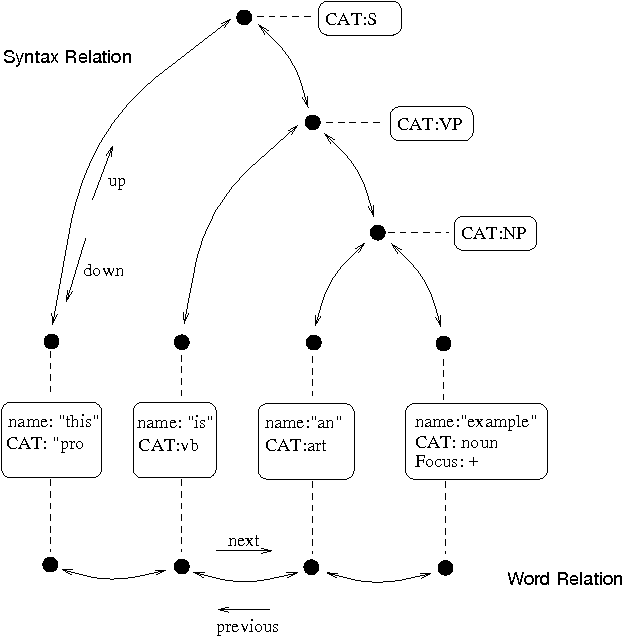
3. Festival:语音合成探索的强大工具包
Festival 由爱丁堡大学开发,不仅仅是一个文本转语音引擎。它提供了一个用于构建和试验语音合成系统的综合框架。这使得它成为研究人员和任何有兴趣进一步了解 TTS 工作原理的人的宝贵工具。
所附图表说明了 Festival 的一般话语结构,它类似于一棵具有连接节点的树。这些节点代表对最终口语输出有贡献的不同元素。
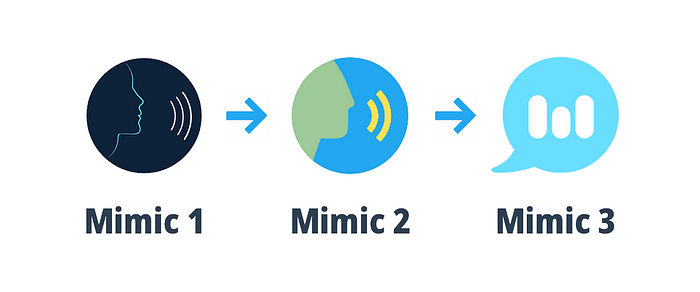
4. 模仿:具有传统和现代选择的自然语音
Mimic 由 Mycroft AI 开发,因其能够生成非常自然的语音而脱颖而出。它提供了两种不同的方法:
- 模仿 1:此方法建立在成熟的节日语音合成系统之上。
- Mimic 2:这一尖端选项利用深度神经网络进行语音合成,从而产生更加逼真的语音。
Mimic 提供传统和现代的文本转语音技术,满足更广泛的受众需求。它还支持多种语言。不过,需要注意的是,Mimic 提供的文档可能有限。
5. Mozilla TTS
Mozilla TTS 利用深度学习,特别是序列到序列模型,采用先进的文本转语音方法。与传统方法相比,这使其能够生成听起来更自然、更像人类的语音。以下是 Mozilla TTS 如此有趣的原因:
- 先进的深度学习:通过利用现代神经网络架构,Mozilla TTS 可以分析人类语音模式的复杂性并更准确地复制它们。这使得语音更流畅、更细致入微、更少机械感。
- 开源且免费:与上述其他引擎一样,Mozilla TTS 可供任何人免费使用和修改。这促进了开源社区内的协作和创新。
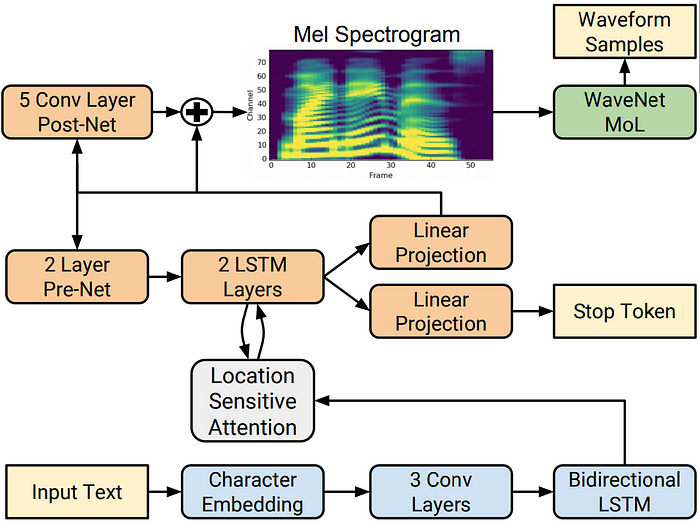
6.Tacotron 2(NVIDIA 出品)
Tacotron 2虽然本身并不是引擎,但它是一种用于生成自然语音的神经网络模型架构。Tacotron 2 的开源实现已经可用,并且它启发了语音合成技术的许多发展。
该系统允许用户使用原始文本合成语音,无需任何额外的韵律信息。
优点:由 NVIDIA 开发,适合用作神经网络模型。
缺点:需要一些技术知识才能实现。
7. GTTS(Google 文本转语音)
此选项为习惯使用 Python 的用户提供了一个简单的界面。虽然 Google 不再积极维护它,但它仍然是满足基本需求的不错选择,并且具有不错的语言支持。
链接:https://pypi.org/project/gTTS/
9. NVidia NeMo TTS
该引擎利用深度学习生成高质量语音,并得到 Nvidia 等大型科技公司的支持。由于使用深度学习模型,它可能有更严格的设置要求。