




由 Dall-E 创建
介绍
大号
et 的评论 VoiceCraft 是由一支才华横溢的研究团队开发的尖端神经编解码器语言模型。它在语音编辑和零样本文本转语音任务上都取得了最先进的性能。
想象一下这样的场景:您正在为您的视频或在线播客谈论您的想法,人工智能会对其进行分析、完善,并在纠正后将其返回给您!
在本文中,我们将深入研究 VoiceCraft 的标记重排程序和建模框架背后的数学公式,揭示该模型为何能够改变语音合成领域的游戏规则。
我对这个模型的看法
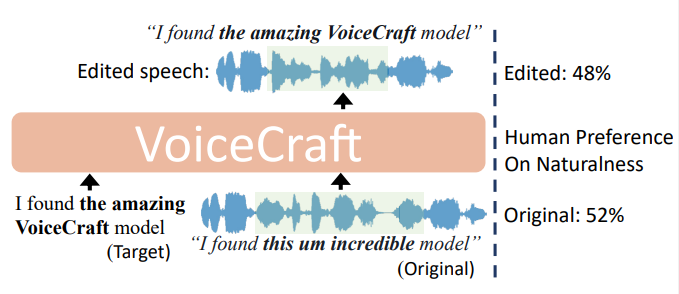
毫无疑问,这是语音编辑领域的一项突破。VoiceCraft 最令人印象深刻的壮举之一是其语音编辑功能。该模型采用了创新的标记重排程序,结合了因果掩蔽和延迟堆叠,使其能够以无与伦比的准确性在现有序列中生成。
在主观人类听力测试中,VoiceCraft 在具有挑战性的 REALEDIT 数据集上的表现明显优于之前最先进的语音编辑模型。
来源-这里
VoiceCraft 的架构
来源-这里
i.) 编码语音标记器
VoiceCraft 的架构基于 Encodec 语音标记器,它将输入语音波形量化为一系列离散标记。Encodec 采用残差矢量量化 (RVQ) 方法,利用多个码本捕捉语音信号的不同方面。Encodec 的输出是一个 T x K 编解码器矩阵,其中 T 表示时间帧的数量,K 表示 RVQ 码本的数量。
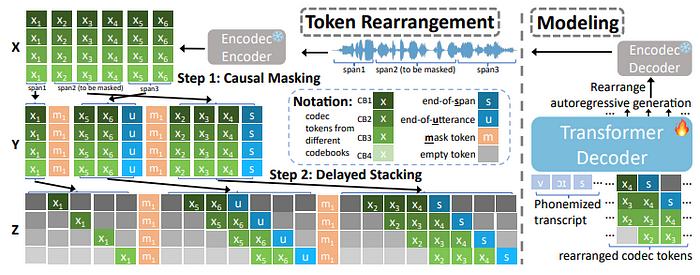
ii.) Token 重排:一个两步过程
为了实现编解码器令牌的高效和有效建模,VoiceCraft 采用了两步令牌重排程序:
a. 因果掩蔽:在训练期间,随机跨度的标记被掩蔽并移动到序列的末尾,从而允许模型在自回归生成期间对过去和将来未掩蔽的标记进行条件调节。
数学公式:
给定一个连续语音波形作为输入,VoiceCraft 首先使用 Encodec 将其量化为 T x K 编解码器矩阵 X,其中 T 是时间帧的数量,K 是 RVQ 码本的数量。矩阵 X 可以表示为 (X₁, …, X_T),其中 X_t 是一个长度为 K 的向量,表示时间步骤 t 时来自不同码本的代码。
在训练期间,目标是随机屏蔽一系列标记 (X_t₀, …, X_t₁),并根据未屏蔽的标记自回归地预测这些屏蔽的标记。为了实现这一点,屏蔽范围被移到序列的末尾,确保模型在自回归生成期间能够同时对过去和未来的未屏蔽标记进行条件化。
b. 延迟堆叠:重新排列的标记矩阵根据码本索引经历延迟模式,确保时间 t 的码本 k 的预测取决于同一时间步的码本 k-1 的预测。
数学公式:
在因果掩蔽步骤之后,重新排列的矩阵 Y 的每个时间步长都是 K 个标记的向量。为了实现高效的多码本建模,VoiceCraft 应用了一种延迟模式,根据其码本索引重新排列标记。对于形状为 L_s × K 的跨度 Y_s,延迟堆叠操作将其转换为 Z_s = (Z_s,₀, Z_s,₁, …, Z_s,L_s+K-1),其中 Z_s,t 定义为:
Z_s,t = (Y_s,t,₁, Y_s,t+1,₂, …, Y_s,t-K+1,K)
这种重新排列确保了时间 t 时码本 k 的预测取决于同一时间步长中码本 k-1 的预测,从而实现高效的并行处理。
iii.) Transformer 解码器和自回归预测
它采用 Transformer 解码器以语音记录为条件,对重新排列的 token 序列进行自回归建模。Transformer 架构采用多头自注意力机制,使模型能够捕获长距离依赖关系并生成高质量的语音输出。
解码器使用 K 个 MLP 头同时预测每个时间步的所有 K 个标记,将最终隐藏状态投影到 K 个逻辑集,每个码本一个。
数学公式:
VoiceCraft 使用 Transformer 解码器对重新排列的标记序列 Z 进行自回归建模,以语音 W 的转录为条件。解码器的输入是 [W; Z],其中“;”表示连接。Transformer 解码器对 Z 的因式分解条件分布进行建模:
P_θ(Z|W) = ∏_s ∏_t P_θ(Z_s,t|W, H_s,t) = ∏_s ∏_t ∏_k=1^K P_θ(Z_s,t,k|W, H_s,t)
这里,θ 表示模型参数,H_s,t 表示 Z 中 Z_s,t 之前的所有 token。该模型使用 K 个 MLP 头同时预测 Z_s,t 的所有 K 个 token,将 Transformer 的最终隐藏状态投影到 K 组 logits,每个码本一个。
训练损失由负对数似然 L(θ) = -log P_θ(Z|W) = -Σ_k=1^K α_k L_k(θ) 得出,其中 (α_k)_k=1^K 是可调超参数,用于加权不同码本的贡献。

由 Dall-E 创建
推理过程
来源-这里
1.)演讲编辑
在语音编辑推理过程中,VoiceCraft 执行以下步骤:
a. 对齐:模型比较原始成绩单和目标成绩单以识别需要编辑的单词,并使用单词级强制对齐来确定相应的编解码器标记跨度。
b. 掩蔽:已识别的标记跨度被掩蔽标记替换,并移动到序列的末尾,同时移动一小段相邻标记以确保平滑过渡。
c. 自回归生成: VoiceCraft 使用重新排列的标记序列作为 Transformer 解码器的输入,自回归生成以目标转录本和非掩码跨度为条件的掩码跨度。
d.波形合成:将生成的编解码器令牌拼接回原来的位置,并将完整的令牌序列通过Encodec解码器,合成编辑后的语音波形。
2.)零样本文本转语音
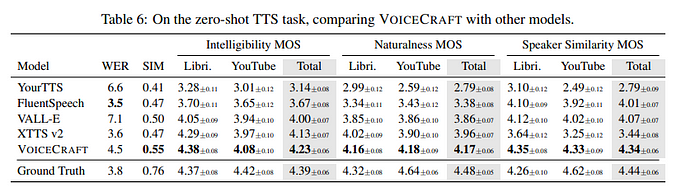
来源-这里
对于零样本文本转语音,VoiceCraft 将任务视为在原始话语末尾插入编辑:
a. 提示准备:为模型提供语音提示、其转录和目标转录,它们连接在一起形成输入序列。
b. 自回归生成: VoiceCraft 根据语音提示及其转录,自回归生成与目标转录相对应的编解码器标记。
c.波形合成:生成的编解码器令牌通过Encodec解码器合成最终的语音波形。
为了确保高质量的输出,VoiceCraft 在推理过程中采用了核采样和减少标记重复等技术,以减轻过度静音或声音拖拽等潜在问题。

由 Dall-E 创建
代码:
实际上,我对没有给你输出音频感到不高兴,但你可以根据以下内容在 google colab 中做到这一点:
VoiceCraft 语音编辑
#准备环境
!apt-get install -y git-core ffmpeg espeak-ng
!pip install -q condacolab
import condacolab
condacolab.install()
condacolab.check()
!echo -e "拿一杯咖啡和一片披萨……\n\n"
!conda install -y -c conda-forge montreal-forced-aligner=2.2.17 openfst=1.8.2 kaldi=5.5.1068 && \
pip install torch==2.1.0 && \
pip install tensorboard==2.16.2 && \
pip install phonemizer==3.2.1 && \
pip install torchaudio==2.1.0 && \
pip install datasets==2.16.0 && \
pip install torchmetrics==0.11.1 && \
pip install torchvision==0.16.0
!pip install -U git+https://git@github.com/facebookresearch/audiocraft #egg=audiocraft
!git clone https://github.com/jasonppy/VoiceCraft.git
!mfa 模型下载词典 english_us_arpa && \
mfa 模型下载声学 english_us_arpa
# 简单安装 audiocraft 由于没有配置而中断,因此将默认设置移入 site-packages
% cd /content/VoiceCraft
!git clone https://github.com/facebookresearch/audiocraft.git
! mv audiocraft/config /usr/local/lib/python3.10/site-packages/
! rm -rf audiocraft
# 导入 libs
导入torch
导入torchaudio
导入os
导入numpy作为np
导入随机
os.environ[ "CUDA_DEVICE_ORDER" ]= "PCI_BUS_ID"
os.environ[ "CUDA_VISIBLE_DEVICES" ]= "0"
os.environ[ "USER" ] = "YOUR_USERNAME" # TODO 将其更改为您的用户名
from data.tokenizer import (
AudioTokenizer,
TextTokenizer,
)
from models import voicecraft
# 推理的超参数
left_margin = 0.08
right_margin = 0.08
codec_audio_sr = 16000
codec_sr = 50
top_k = 0
top_p = 0.8temperature
= 1
kvcache = 0
#注意:如果生成效果不佳,请调整以下三个参数
seed = 1 # 随机种子魔法
silent_tokens = [ 1388 , 1898 , 131 ]
stop_repetition = - 1 # 如果生成的音频中存在长时间的静音,请将 stop_repetition 减少到 3、2 甚至 1
# 这将对模型产生影响,即模型将运行相同音频的 sample_batch_size 个示例,并选择最短的那个
def seed_everything ( seed ):
os.environ[ 'PYTHONHASHSEED' ] = str (seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_everything(seed)
device = "cuda" if torch.cuda.is_available() else "cpu"
# 指向原始文件或录制文件
# 写下文件的成绩单,或运行 whisper 来获取成绩单(如果不准确,你可以修改它),将其保存为 .txt 文件
orig_audio = "./demo/84_121550_000074_000000.wav"
orig_transcript = "但当我离它们这么近的时候,感觉欺骗了共同的物体,距离并没有让它失去任何痕迹,"
# 将音频和成绩单移动到临时文件夹
temp_folder = "./demo/temp"
os.makedirs(temp_folder, exist_ok= True )
os.system( f"cp {orig_audio} {temp_folder} " )
filename = os.path.splitext(orig_audio.split( "/" )[- 1 ])[ 0 ]
with open ( f" {temp_folder} / {filename} .txt" , "w" ) as f:
f.write(orig_transcript)
# 运行 MFA 以获取比对 align_temp
= f" {temp_folder} /mfa_alignments"
os.makedirs(align_temp, exist_ok= True )
os.system( f"mfa align -j 1 --clean --output_format csv {temp_folder} english_us_arpa english_us_arpa {align_temp} " )
# 如果失败,可能是因为音频对于对齐模型来说太难了,增加波束大小通常可以解决问题
# os.system(f"mfa align -j 1 --clean --output_format csv {temp_folder} english_us_arpa english_us_arpa {align_temp} --beam 1000 --retry_beam 2000")
audio_fn = f" {temp_folder} / {filename} .wav"
transcript_fn = f" {temp_folder} / {filename} .txt"
align_fn = f" {align_temp} / {filename} .csv"
editTypes_set = set ([ 'substitution' , 'insertion' , 'deletion' ])
# 提议目标修改后的记录是什么
target_transcript = "但是当我看到远处湖面的海市蜃楼时,感觉被欺骗了,距离并没有让我迷失它的任何痕迹,"
edit_type = "substitution"
assert edit_type in editTypes_set, f"无效的编辑类型{edit_type} 。必须是{editTypes_set}之一。"
# 如果要在第一个修改的基础上进行第二个修改,请写下第二个修改 (target_transcript2, type_of_modification2)
# 确保两个修改不重叠,如果重叠,则需要将它们合并为一个修改
# 运行脚本将用户输入转换为模型可以采用的格式
from edit_utils import get_span
orig_span, new_span = get_span(orig_transcript, target_transcript, edit_type)
if orig_span[ 0 ] > orig_span[ 1 ]:
RuntimeError( f"example {audio_fn} failed" )
if orig_span[ 0 ] == orig_span[ 1 ]:
orig_span_save = [orig_span[ 0 ]]
else :
orig_span_save = orig_span
if new_span[ 0 ] == new_span[ 1 ]:
new_span_save = [new_span[ 0 ]]
else :
new_span_save = new_span
orig_span_save = "," .join([ str (item) for item in orig_span_save])
new_span_save = "," .join([ str (item) for item in new_span_save])
from inference_speech_editing_scale import get_mask_interval
start, end = get_mask_interval(align_fn, orig_span_save, edit_type)
info = torchaudio.info(audio_fn)
audio_dur = info.num_frames / info.sample_rate
morphed_span = ( max (start - left_margin, 1 /codec_sr), min (end + right_margin, audio_dur)) # 以秒为单位
# 以编解码器帧为单位的跨度
mask_interval = [[ round (morphed_span[ 0 ]*codec_sr), round(morphed_span[ 1 ]*codec_sr)]]
mask_interval = torch.LongTensor(mask_interval) # [M,2],目前为 M==1
# 加载模型、标记器和其他必要文件
voicecraft_name= "giga330M.pth" # 或 giga830M.pth,或 https://huggingface.co/pyp1/VoiceCraft/tree/main 上的较新模型
ckpt_fn = f"./pretrained_models/ {voicecraft_name} "
encodec_fn = "./pretrained_models/encodec_4cb2048_giga.th"
if not os.path.exists(ckpt_fn):
os.system( f"wget https://huggingface.co/pyp1/VoiceCraft/resolve/main/ {voicecraft_name} \?download\=true" )
os.system( f“mv {voicecraft_name} \?download\=true ./pretrained_models/ {voicecraft_name} “)
如果 不存在os.path.exists(encodec_fn):os.system
( f “wget https://huggingface.co/pyp1/VoiceCraft/resolve/main/encodec_4cb2048_giga.th”)os.system(f“mv encodec_4cb2048_giga.th ./pretrained_models/encodec_4cb2048_giga.th”)ckpt = torch.load(ckpt_fn,map_location = “cpu”)model = voicecraft.VoiceCraft(ckpt [ “config” ] )model.load_state_dict(ckpt [ “model” ])model.to(设备)模型。eval () phn2num = ckpt[ 'phn2num' ] text_tokenizer = TextTokenizer(backend= "espeak" ) audio_tokenizer = AudioTokenizer(signature=encodec_fn) # 还将神经编解码器模型放在 gpu 上# 运行模型以获取输出from inference_speech_editing_scale import inference_one_sample decrypt_config = { 'top_k' : top_k, 'top_p' : top_p, 'temperature' :temperature, 'stop_repetition' : stop_repetition, 'kvcache' : kvcache, "codec_audio_sr" : codec_audio_sr, "codec_sr" : codec_sr, "silence_tokens" : silent_tokens} orig_audio, new_audio = inference_one_sample(model, ckpt[ "config" ], phn2num, text_tokenizer, audio_tokenizer, audio_fn, target_transcript, mask_interval, device, decrypt_config) # 保存片段以供比较orig_audio, new_audio = orig_audio[ 0 ].cpu(),new_audio[ 0 ].cpu()
#logging.info(f"重新合成原始音频的长度:{orig_audio.shape}")
#显示音频
从IPython.display导入音频
print ( "原始:" )
显示(Audio(orig_audio,rate=codec_audio_sr))
print ( "编辑:" )
显示(Audio(new_audio,rate=codec_audio_sr))
只是输出的图片,抱歉这里不能放音频
VoiceCraft 推理 TTS
!apt-get 安装 -y git-core ffmpeg espeak-ng
!pip 安装 -q condacolab
导入 condacolab
condacolab.install()
condacolab.check()
!echo -e "拿一杯咖啡和一片披萨……\n\n"
!conda install -y -c conda-forge montreal-forced-aligner=2.2.17 openfst=1.8.2 kaldi=5.5.1068 && \
pip install torch==2.1.0 && \
pip install tensorboard==2.16.2 && \
pip install phonemizer==3.2.1 && \
pip install torchaudio==2.1.0 && \
pip install datasets==2.16.0 && \
pip install torchmetrics==0.11.1 && \
pip install torchvision==0.16.0
!pip install -U git+https://git@github.com/facebookresearch/audiocraft #egg=audiocraft
!git clone https://github.com/jasonppy/VoiceCraft.git
!mfa 模型下载词典 english_us_arpa && \
mfa 模型下载声学 english_us_arpa
# 导入库
# 如果这引发错误,则表示安装依赖项或更改上述内核时出了点问题!
import os
os.environ[ "CUDA_DEVICE_ORDER" ]= "PCI_BUS_ID"
os.environ[ "CUDA_VISIBLE_DEVICES" ]= "0"
os.environ[ "USER" ] = "YOUR_USERNAME" # TODO 将其更改为您的用户名
import torch
import torchaudio
import numpy as np
import random
from VoiceCraft.data.tokenizer import (
AudioTokenizer,
TextTokenizer,
)
# 简单地安装 audiocraft 会因为没有配置而中断,因此将默认设置移入 site-packages
% cd /content/VoiceCraft
!git clone https://github.com/facebookresearch/audiocraft.git
! mv audiocraft/config /usr/local/lib/python3.10/site-packages/
! rm -rf audiocraft
# 加载模型、编码解码器和 phn2num
# # 加载模型、标记器和其他必要文件
device = "cuda" if torch.cuda.is_available() else "cpu"
from VoiceCraft.models import voicecraft
# 重新加载 voicecraft 导入
importlib importlib.reload
(voicecraft)
from VoiceCraft.models import voicecraft
voicecraft_name= "gigaHalfLibri330M_TTSEnhanced_max16s.pth" # 或 giga330M.pth、giga830M.pth
ckpt_fn = f"./pretrained_models/ {voicecraft_name} "
encodec_fn = "./pretrained_models/encodec_4cb2048_giga.th"
if not os.path.exists(ckpt_fn):
os.system( f"wget https://huggingface.co/pyp1/VoiceCraft/resolve/main/ {voicecraft_name} \?download\=true”)
os.system(f“mv {voicecraft_name} \?download\=true./pretrained_models / {voicecraft_name} ”)
如果 不存在os.path.exists(encodec_fn):os.system
( f “wget https://huggingface.co/pyp1/VoiceCraft/resolve/main/encodec_4cb2048_giga.th”)os.system(f“mv encodec_4cb2048_giga.th./pretrained_models/encodec_4cb2048_giga.th”)ckpt = torch.load(ckpt_fn,map_location = “cpu”)model = voicecraft.VoiceCraft(ckpt [ “config” ])model.load_state_dict (ckpt [ “model” ])model.to (device) model.eval () phn2num = ckpt[ 'phn2num' ] text_tokenizer = TextTokenizer(backend= "es2peak" ) audio_tokenizer = AudioTokenizer(signature=encodec_fn, device=device) # 还会将神经编解码器模型放在 gpu 上
# 准备音频
# 指向要克隆其语音的原始音频
# 记下文件的成绩单,或运行 whisper 以获取成绩单(如果不准确,您可以修改它),将其保存为 .txt 文件
orig_audio = "./demo/84_121550_000074_000000.wav"
orig_transcript = "但当我离它们如此之近时,感觉所欺骗的共同物体,不会因距离而丢失任何标记,"
# 将音频和成绩单移动到临时文件夹
temp_folder = "./demo/temp"
os.makedirs(temp_folder, exist_ok= True )
os.system( f"cp {orig_audio} {temp_folder} " )
filename = os.path.splitext(orig_audio.split( "/" )[- 1 ])[ 0 ]
with open ( f" {temp_folder} / {filename} .txt" , "w" ) as f:
f.write(orig_transcript)
# 运行 MFA 以获取对齐
align_temp = f" {temp_folder} /mfa_alignments"
os.system( f"mfa align -j 1 --clean --output_format csv {temp_folder} english_us_arpa english_us_arpa {align_temp} " )
# # 如果上述操作失败,则可能是因为音频对于对齐模型来说太难,增加波束尺寸通常可以解决问题
# os.system(f"mfa align -j 1 --clean --output_format csv {temp_folder} english_us_arpa english_us_arpa {align_temp} --beam 1000 --retry_beam 2000")
# 查看 VoiceCraft/demo/temp/mfa_alignment 中的 csv 文件,决定使用哪部分音频作为提示
cut_off_sec = 3.01 #注意:根据强制对齐文件 demo/temp/mfa_alignments/84_121550_000074_000000.csv,单词“common”停止为 3.01 秒,不同的音频应该有所不同
target_transcript = “但是当我如此接近它们时,我无法相信相同的模型也可以进行文本到语音合成!”
#注意: 3 秒的参考通常足以实现高质量的语音克隆,但时间越长通常越好,例如尝试 3~6 秒。
audio_fn = f" {temp_folder} / {filename} .wav"
info = torchaudio.info(audio_fn)
audio_dur = info.num_frames / info.sample_rate
assert cut_off_sec < audio_dur, f"cut_off_sec {cut_off_sec}大于音频持续时间{audio_dur} "
prompt_end_frame = int (cut_off_sec * info.sample_rate)
# 运行模型以获取输出
# 用于推理的超参数
codec_audio_sr = 16000
codec_sr = 50
top_k = 0
top_p = 0.8temperature
= 1
silent_tokens=[ 1388 , 1898 , 131 ]
kvcache = 1 # 注意,如果出现 OOM,请将其更改为 0,或者尝试 330M 模型
# 注意,如果生成效果不佳,请调整以下三个参数
stop_repetition = 3 # 注意:如果模型生成长时间的沉默,请将 stop_repetition 减少到 3、2 甚至 1
sample_batch_size = 2 # 对于 gigaHalfLibri330M_TTSEnhanced_max16s.pth,1 或 2 应该没问题,因为该模型经过训练可以进行 TTS,对于其他两个模型,可能需要更高的数字。注意:如果有长时间的沉默或不自然的拉长的单词,请将 sample_batch_size 增加到 5 或更高。这对模型的影响是,模型将运行相同音频的 sample_batch_size 个示例,并选择最短的一个。因此,如果生成的语速太快,请将其更改为较小的数字。
seed = 1 # 如果对结果仍然不满意,请更改种子
def seed_everything ( seed ):
os.environ[ 'PYTHONHASHSEED' ] = str (seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(种子)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_everything(种子)
decrypt_config = { 'top_k' : top_k,'top_p' : top_p,'temperature' :temperature,'stop_repetition' : stop_repetition,'kvcache' : kvcache,"codec_audio_sr" : codec_audio_sr,"codec_sr" : codec_sr,"silence_tokens" : silent_tokens,"sample_batch_size" : sample_batch_size}
从VoiceCraft.inference_tts_scale导入inference_one_sample
concated_audio, gen_audio = inference_one_sample(模型, ckpt[ "config" ], phn2num、text_tokenizer、audio_tokenizer、audio_fn、target_transcript、device、decode_config、prompt_end_frame)
# 保存片段以供比较
concated_audio、gen_audio = concated_audio[ 0 ].cpu()、gen_audio[ 0 ].cpu()
# logs.info(f"length of the resynthesize orig audio: {orig_audio.shape}")
# 显示音频
from IPython.display import Audio
print ( "concatenate prompt and generated:" )
display(Audio(concated_audio, rate=codec_audio_sr))
print ( "generated:" )
display(Audio(gen_audio, rate=codec_audio_sr))
只是输出的图片,抱歉这里不能放音频
什么让它更加令人印象深刻?
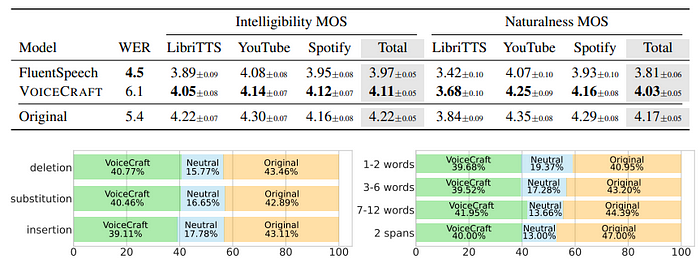
这是用于评估的数据的多样性和复杂性。VoiceCraft 在不同口音、说话风格、录音条件和背景噪音的语音上始终表现良好——证明了它在现实场景中的稳健性和多功能性。

由 Dall-E 创建
在 REALEDIT 数据集上进行训练:
语音编辑的新基准 为了全面评估 VoiceCraft 的语音编辑功能,研究人员推出了 REALEDIT,这是首创的数据集,旨在逼真、具有挑战性和多样性。REALEDIT 由 310 个来自有声读物、YouTube 视频和 Spotify 播客的手工制作的语音编辑示例组成,涵盖了广泛的编辑场景,包括插入、删除、替换和多跨度编辑。
REALEDIT 中包含了各种内容、口音、说话风格、录音条件和背景声音,为评估语音编辑模型树立了新标准。通过在这个具有挑战性的数据集上展示出色的性能,VoiceCraft 已成为现实世界语音编辑任务的可靠实用解决方案。
伦理考量和未来方向
尽管 VoiceCraft 取得的进步令人瞩目,但谨慎对待如此强大的技术的部署至关重要。VoiceCraft 背后的研究人员已经意识到滥用的可能性,例如冒充和欺诈,并正在积极研究深度伪造检测和水印算法以减轻这些风险。
通过开放 VoiceCraft 的代码和模型权重,该团队旨在促进合作并加速开发针对恶意使用语音克隆技术的强大对策。这种透明和积极主动的方法反映了他们致力于负责任地推进该领域并最大限度地造福社会的承诺。
结论
VoiceCraft 代表了人工智能语音编辑和合成领域的重大飞跃,在多样化的真实数据上展现了无与伦比的性能。它能够生成高度自然的编辑语音,并在零样本文本转语音任务中取得最先进的结果,为该领域树立了新的标杆。
随着技术的不断发展,研究人员、开发者和政策制定者必须共同努力,充分利用 VoiceCraft 等模型的潜力,同时积极应对它们带来的道德挑战。通过负责任的开发和部署,VoiceCraft 及其未来版本有可能改变各个行业并改善全球无数人的生活。
关键字:
VoiceCraft、AI、语音编辑、合成、神经编解码器、语言模型、标记重排、因果掩蔽、延迟堆叠、Transformer、自回归预测、语音编辑推理、零样本文本转语音、编解码器、残差矢量量化 (RVQ)、REALEDIT 数据集、多样化数据、口音、说话风格、录音条件、背景噪音、道德考虑、深度伪造检测、水印、开源、负责任的开发
