




由作者使用 DALL-E3 生成
虽然开源大型语言模型 (LLM) 几乎处于封闭模型级别,LLaMa 3 405B(仍有待发布)可能与 GPT-4 一样好甚至更好,但多模态 LLM 严重落后。
或者他们是吗?
一组中国研究人员发布了InternVL 1.5,这是一种 MLLM,在许多任务中与GPT-4V或Claude 3 OpusVision的性能相匹配,在某些情况下,甚至成为最先进的,特别是在 OCR(识别文本中的文本)方面。图像)以及文档和图表问答。
令人着迷的是,这个模型是完全开源的,因为权重和训练数据集都已发布,这是连 LLaMa 模型都无法声称的。
尽管您可能认为在最近发布 ChatGPT-4o 和 Google 的 Project Astra 后情况已不再如此,但您可能会感到惊讶。
您可能厌倦了谈论这个或那个**如何**发生的人工智能时事通讯。这些时事通讯比比皆是,因为粗略地谈论已经发生的事件和事情很容易,但提供的价值有限,而且炒作被夸大了。
然而,谈论即将发生的事情的时事通讯却很少见。如果您想先于其他人对人工智能的未来进行易于理解的见解,那么TheTechOasis时事通讯可能非常适合您。
🏝️🏝️ 今天订阅如下:
科技绿洲
为什么开源 MLLM 很糟糕
虽然我建议阅读我的博客,了解什么是 MLLM 模型,但要点如下:使用 LLM 作为骨干,我们连接其他组件(即编码器),允许 LLM 处理除文本之外的其他类型的数据。
编码器是获取其他形式的数据(例如图像或音频)并将其转换为矢量表示的组件。这些向量被称为嵌入,我在这篇博文中详细描述了它们,它们只是以机器可以处理的方式表示相同数据的一种方式。
重要的是,这些向量经过压缩,这意味着它们经过训练可以捕获原始数据的关键属性并避免不必要的噪声,以最大限度地提高效率。
例如,图像编码器还允许 LLM 处理图像(因此 ChatGPT 可以解释图像)。然而,在开源世界中,资金紧张。
残酷的事实
认识到这一点,研究人员想方设法获得“可发表”的结果。当然,这一策略意味着,虽然仍然取得了良好的成果,但它们远远落后于现金充裕的专有实验室。
例如,虽然这些实验室将所有组件一起训练,但开源团队采用开源组件并使用“适配器”(通常是 MLP 层)将它们拼接在一起。
然后,在保持编码器和 LLM 冻结(预训练但在 MLLM 训练期间不更新)的同时,团队只训练适配器。
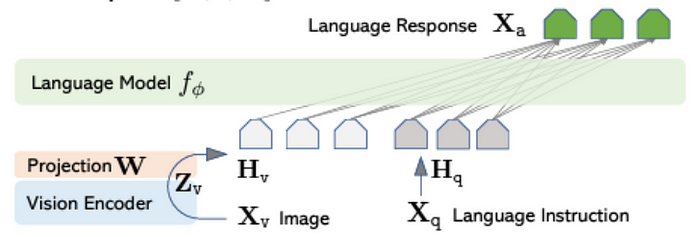
上述过程称为“嫁接”。通过冻结架构中的大型组件,开源研究人员可以以一小部分成本来训练 MLLM 模型。
但适配器有什么作用呢?
通俗地说,如果我们有一个图像编码器,编码器会处理图像,然后适配器将该信息转换为 LLM 可读的令牌。
直观地,可以将适配器视为接收图像并将其转换为图像标题。这样,纯文本法学硕士就可以“看到”图像,即使只是“看到标题”。
另一种看待这个问题的方式是作为翻译,就好像编码器说“日语”而法学硕士说“英语”。他们可能指的是相同的概念,但他们没有意识到这一点,因为“他们说的不是同一种语言”。
在实践中,真正发生的是适配器将图像嵌入投影到 LLM 的嵌入空间中。换句话说,它将一种不熟悉的表示形式调整为法学硕士可以理解的表示形式。
由于法学硕士只能理解文本表示,因此这种投影本质上起到了将图像转换为文字的作用。
此外,开源模型通常只接受单一图像分辨率,以进一步降低成本。因此,如果提供的图像尺寸不准确,则会调整其大小。
想象一下,你有一部高分辨率电影,却被迫在 300 x 300 像素的屏幕上观看。自然,大量的信息会丢失。
那么,总而言之,团队是如何处理这些限制的呢?
巨大的编码器,巨大的结果
InternVL 1.5的创新点可概括如下:
- 动态输入分辨率
- 整个模型训练
- 高质量数据集
保持聪明,愚蠢
首先,他们通过定义预设的尺寸关系(1:3、2:3等)设计模型以接受任何图像尺寸。
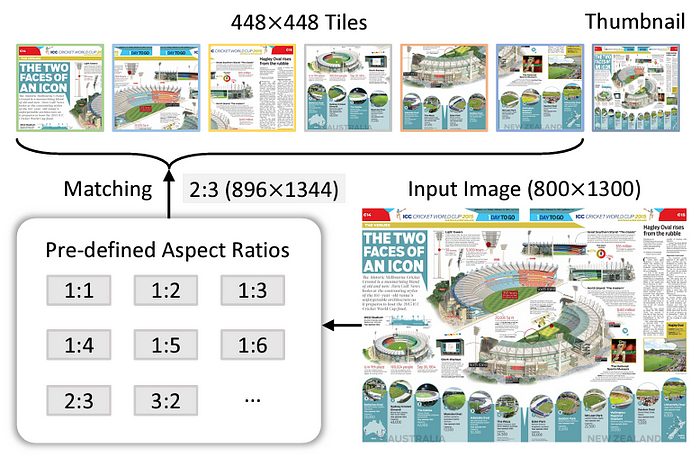
因此,每个图像都匹配特定尺寸并相应地调整尺寸,而不会影响太多信息。
他们还添加了压缩的全局图像(某种缩略图),为模型提供整个图像的压缩视图。
此外,与常见的训练方法不同,整个模型都经过训练,而不仅仅是 MLP 投影仪(适配器)。换句话说,现在一切都经过训练,而不是冻结计算要求较高的组件以节省成本。重要的是,他们还使用了比正常情况大得多的图像编码器,增强了模型处理更复杂图像的能力。
然而,虽然训练所有组件自然会产生更好的结果,但它也会增加成本。
因此,为了使整个训练过程在预算之内,他们使用不同的精选数据集和不同的 LLM 模型逐步训练模型,以便总体成本更低,与Li 等人的研究类似。
李等人。提出了渐进式训练的理念。他们不是首先在一个尺寸上训练模型,然后增加模型的尺寸并再次从头开始训练,而是逐渐增加模型的尺寸而不丢弃以前的检查点,从而大大降低了总体训练成本。换句话说,新的较大模型偏离了从较小模型获得的知识。
这不是完全相同的方法,但智能地结合训练运行以节省成本的想法仍然适用。
最后,他们策划了一个双语(英语/中文)数据集,增强了模型的语言能力,同时提高了其在文本图像数据上的性能。
那么,综合考虑,整个过程是如何运作的呢?
- 提供图像和文本任务(例如“图像中的哪种护理更具空气动力学性能?” )
- 然后,模型将图像分成大小相等的块(数量取决于原始大小)
- 然后,适配器将图像标记转换为文本标记,LLM 对其进行处理以生成响应。
就是这样,第一个最先进的完全开源模型。

