



是
你知道,当一家大型科技公司宣布推出一款全新的人工智能工具时,我总是感到兴奋。我倾向于期待一些有趣的东西或令人惊叹的工具来玩,甚至构建一个产品。
今天也不例外,Adobe 发布了VideoGigaGAN的研究预览版,它可以将模糊视频转换为高度详细的超分辨率输出。
什么是VideoGigaGAN?
VideoGigaGAN 是一种新颖的视频超分辨率(VSR)生成模型,旨在将低分辨率视频上采样为高分辨率,同时保持高频细节和帧间的时间一致性。
查看下面的之前和之后的示例:


视频放大之前(左)和之后(右)
上面的示例视频为 512×512,已放大到 1028×1028。除了放大四倍之外,最终视频还获得了丰富细节的改进。结果确实令人印象深刻,展示了人工智能在提高视频质量方面的力量。
只需看看那些皮肤纹理和精致的眉毛细节即可。真是令人兴奋。
它是如何工作的
VideoGigaGAN 扩展了基于图像的 GigaGAN 上采样器的非对称 U-Net 架构来处理视频数据。该模型包含几个关键组件,以强制视频帧之间的时间一致性。
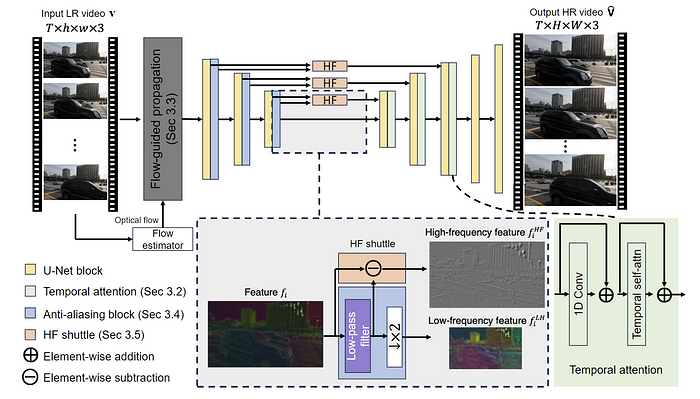
首先,通过在解码器块内集成时间注意力层,将图像上采样器扩展为视频上采样器。这使得模型能够有效地捕获和传播时间信息。
其次,引入了流引导传播模块以进一步增强时间一致性。该模块通过采用光流估计和循环神经网络来跨帧对齐和传播特征,为膨胀的 GigaGAN 提供时间感知特征。
第三,为了减轻由编码器中的下采样操作产生的混叠伪影,使用抗混叠块代替标准下采样层。这些模块应用低通滤波器,然后进行二次采样,这有助于抑制混叠并减少输出视频中的时间闪烁。
最后,为了补偿抗锯齿操作造成的高频细节损失,采用了高频特征梭。该机制通过跳跃连接直接将高频特征从编码器传输到解码器,绕过抗锯齿块中的 BlurPool 过程。这确保了输出视频保留清晰的细节和纹理,同时受益于改进的时间一致性。

局限性
以下是 VideoGigaGAN 的主要限制:
- 处理极长的视频: VideoGigaGAN 在处理帧数非常大的视频(例如超过 200 帧的视频)时可能会遇到困难。
- 在小物体上的表现不佳: VideoGigaGAN 很难有效地超分辨率视频帧内的小物体,特别是那些包含文本或精细图案等复杂细节的物体。
- 大模型尺寸:与之前的 VSR 方法相比,VideoGigaGAN 由于加入了流引导传播模块和扩展的 U-Net 架构等附加组件,因此模型尺寸明显更大。
- 对光流精度的依赖: VideoGigaGAN 的流引导传播模块的有效性在很大程度上依赖于视频帧之间估计光流的精度。在光流估计不准确的情况下,例如存在大运动、遮挡或复杂场景动态时,模型维持时间一致性的能力可能会受到损害,可能会导致超分辨率输出中出现伪影或不一致。

更多示例
以下是 128×128 视频放大到 512×512 的更多示例。


从低分辨率、像素化的镜头到清晰的高清视频,人工智能模型如何推断和生成缺失的细节是很有趣的。
最后的想法
看起来视频现在越来越受到科技公司的喜爱。在过去的几年里,人工智能的视频生成或操作并没有得到太多的关注和令人兴奋的进展。
很快,这些人工智能驱动的视频生成器或编辑工具将足够高效,可以在您的智能手机上运行。相机不再需要超分辨率硬件来捕捉高质量视频。
说到视频中的人工智能,今天,事情正在发生变化,我们在视频领域看到越来越多的人工智能。以OpenAI的Sora为例,它一发布就引起了很大的轰动。另一个例子是微软最近发布的VASA-1,它可以将单个图像实时处理成说话或唱歌的视频。
人工智能在视频领域的出现是一个令人兴奋的发展,它有望改变我们创建、编辑和消费视频内容的方式。
