什么是黑盒AI?
黑盒AI是任意的人工智能用户或其他相关方看不到其输入和操作的系统。从一般意义上来说,黑盒是一个无法穿透的系统。
黑盒人工智能模型得出结论或决定,但没有提供任何关于它们是如何得出的解释。在黑盒模型中,人工神经元的深层网络将数据和决策分散在数万个神经元中,导致复杂性可能与人脑一样难以理解。简而言之,block box AI的内部机制和影响因素仍然未知。
可解释的人工智能,它是以一种典型的人可以理解其逻辑和决策过程的方式创建的,是黑盒人工智能的对立面。
黑盒机器学习是如何工作的?
深度学习建模通常是通过黑盒开发进行的。学习算法将数百万个数据点作为输入,并关联特定的数据特征以产生输出。
该过程通常包括以下步骤:
- 复杂的算法检查广泛的数据集去寻找模式。为了实现这一点,大量的数据示例被输入到一个算法中,使它能够通过反复试验来自己进行实验和学习。该模型学习改变其内部参数,直到它能够使用大量的输入和预期输出样本来预测新输入的准确输出。
- 作为这次培训的结果机器学习模型最终准备好使用真实世界数据进行预测。使用风险分值的欺诈检测是该机制的一个用例示例。
- 随着时间的推移收集更多的数据,该模型对其方法、途径和知识体系进行扩展。
对于数据科学家、程序员和用户来说,理解黑盒模型如何生成预测可能是一项挑战,因为其内部工作方式并不容易获得,而且在很大程度上是自我导向的。就像很难看到一个被涂成黑色的盒子里面一样,找出每个黑盒人工智能模型的功能也是一项挑战。
在某些情况下,敏感性分析和特征可视化等技术可用于提供对内部流程如何工作的一瞥,但在大多数情况下,它们仍然是不透明的。
黑盒AI有什么含义?
大多数深度学习模型使用黑盒策略。虽然黑盒模型在某些情况下是合适的,但它们可能会带来一些问题,包括以下问题:
人工智能偏差
人工智能偏差可以被引入算法作为开发人员有意识或无意识偏见的反映,或者它们可以通过未被发现的错误潜入。在任何情况下,有偏见的算法的结果将是扭曲的,潜在地以一种冒犯受影响的人的方式。当数据集的细节未被识别时,算法中的偏差可能来自训练数据。例如,在一种情况下,招聘应用程序中使用的人工智能依赖于历史数据来选择IT专业人员。然而,由于历史上大多数IT员工都是男性,人工智能算法显示出对男性申请者的偏好。
如果这种情况是由黑盒人工智能引起的,它可能会持续足够长的时间,使组织的声誉受到损害,并可能因歧视而采取法律行动。对其他群体的偏见也可能产生类似的问题,产生同样的影响。为了防止这种损害,人工智能开发人员必须建立透明度到他们的算法中,执行人工智能法规并承诺对其后果负责。
缺乏透明度和问责制
黑盒神经网络的复杂性可能会阻止个人正确理解和审计它们,即使它们产生准确的结果。即使他们的开发人员也不完全理解这些网络是如何工作的,尽管事实上他们有能力在人工智能领域取得一些最开创性的成就。这可能是医疗保健、银行和刑事司法等高风险领域的一个问题,因为这些模型做出的选择可能会对人们的生活产生深远的影响。当使用不透明的模型时,也很难让个人对算法做出的判断负责。
缺乏灵活性
黑盒AI最大的问题之一就是缺乏灵活性。如果需要改变模型来描述物理上可比较的对象,确定新的规则或整体参数可能需要大量的工作。因此,决策者不应该使用黑盒人工智能模型来处理敏感数据。
安全缺陷
黑盒人工智能模型容易受到威胁者的攻击,这些威胁者利用模型中的缺陷来操纵输入数据。例如,攻击者可以更改输入数据来影响模型的判断,从而做出不正确甚至危险的决策。
什么时候应该使用黑盒AI?
虽然黑盒机器学习模型带来了某些挑战,但它们也提供了一些优势。当获得以下好处很重要时,应该仔细检查和合并黑盒AI模型:
- 精度更高。诸如黑盒之类的复杂系统比更可解释的系统提供更高的预测精度,尤其是在计算机视觉和自然语言处理(自然语言处理).这是因为这些模型能够识别人们可能看不到的数据中的复杂模式。然而,在这些模型中提供准确性的算法的复杂性也使它们不那么透明。
- 快速的结论。黑盒模型通常由一组规则和等式组成,这使得它们可以快速运行并易于优化。例如,使用最小二乘拟合计算曲线下的面积可能会提供一个解决方案,而不需要彻底了解问题。
- 最小的计算能力。黑盒模型不需要大量的计算资源,因为它非常简单。
- 自动化。黑盒人工智能模型可以自动化复杂的决策过程,减少对人工干预的需求。这既节省了时间和资源,又提高了效率。
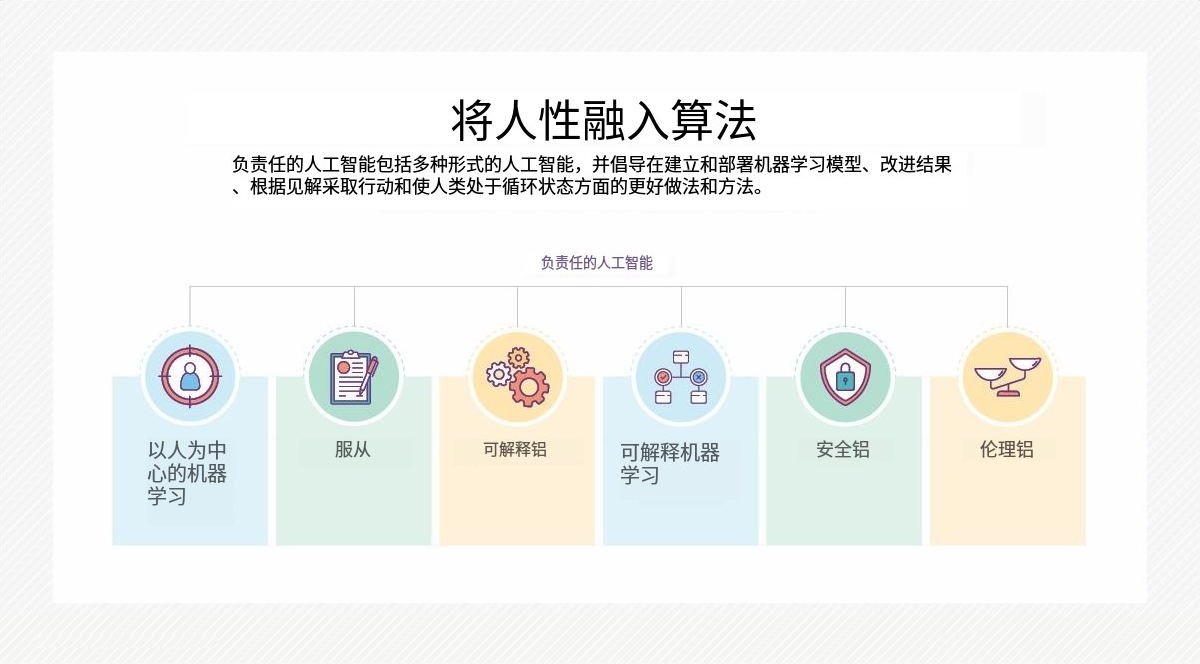
什么是负责任的AI?
以道德高尚和对社会负责的方式开发和使用的人工智能被称为负责任的人工智能(拉爱音乐).RAI计划在很大程度上是由法律责任驱动的。
为了减少黑盒人工智能和机器偏见可能产生的负面财务、声誉和道德风险,负责任的人工智能的指导原则和最佳实践旨在帮助消费者和生产者。
如果人工智能实践遵循以下指导原则,它们就是负责任的:
- 公平。人工智能系统公平地对待所有人和人口统计群体,不会强化或加剧先前存在的偏见或歧视。
- 透明度。该系统易于理解并向用户和受其影响的人解释。此外,人工智能开发者必须披露用于训练人工智能系统的数据的收集、存储和使用情况。
- 问责制。创造和使用人工智能的组织和个人应该对该技术的判断和行为负责。
- 持续发展。为了确保RAI输出始终符合人工智能的道德概念和社会规范,持续的监控是必要的。
- 人工监督。每个人工智能系统都应该设计成能够在适当的时候进行人工监控和干预。
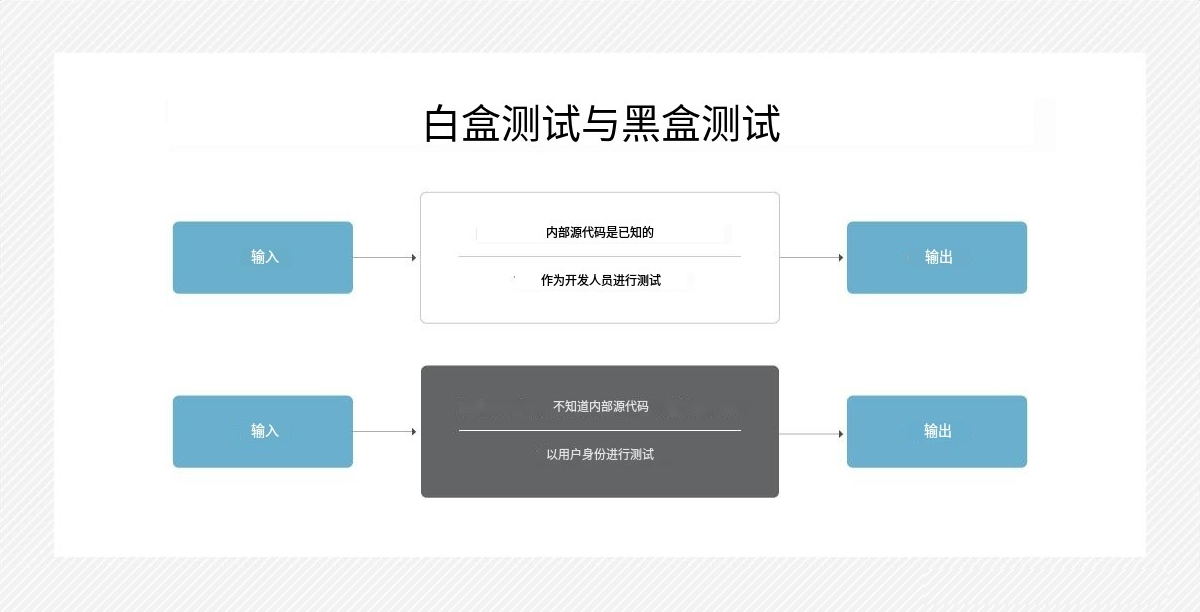
黑盒人工智能对白盒人工智能
黑盒AI和白盒AI是不同的方法开发人工智能系统。特定方法的选择取决于AI系统的具体应用和目标。
虽然黑盒人工智能系统的输入和输出是已知的,但系统的内部工作是不透明的或难以理解的。另一方面,白盒人工智能是透明和可解释的它是如何得出结论的。例如,数据科学家可以检查一种算法,并确定它的行为方式以及哪些变量会影响它的判断。
黑盒人工智能方法通常用于深度神经网络,其中模型根据大量数据进行训练,算法的内部权重和参数也相应调整。该模型在某些应用中是有效的,包括图像和语音识别,其中目标是准确和快速地分类或识别数据。
由于白盒系统的内部工作是透明的,用户很容易理解,这种方法经常用于决策应用程序,如医疗诊断或金融分析,在这些应用程序中,了解人工智能如何得出结论很重要。
以下是这两种人工智能的一些显著特征:
- 黑盒AI往往比白盒AI更准确、更高效。
- 相比黑盒AI,白盒AI更容易理解。
- 黑盒模型包括boosting和随机森林模型,它们本质上是高度非线性的,更难解释。
- 由于其透明的性质,白盒AI比黑盒更容易调试和故障排除。
- 白盒AI通常包括线性的,决策图表和回归树模型。