




图片由 AltumCode、Unsplash提供
人工智能编码工具市场是一个价值数十亿美元的产业。预计到 2030 年将达到 172 亿美元,即使在今天,VS Code 或 JetBrains IDE 的 AI 插件也有数百万次下载。但是我们可以运行本地模型作为免费的编码助手吗?它的性能如何?在本文中,我将测试两个开放模型,Code Gemma 和 Code Llama。我将把它们安装在我的电脑上,我们将看看它们是如何工作的。
话不多说,让我们开始吧!
1. 型号
在撰写本文时,有两个主要的开放模型可供免费下载,并可用于编码目的:
- 代码骆马。该模型由 Meta 于 2023 年发布;有 7B、13B、34B 和 70B 尺寸可供选择。提供“Base”、“Instruct”和“Python”模型。尽管有四种尺寸,但真正能在本地使用的只有 7B 和 13B 型号;其他人则太“重”。
- 代码吉玛。该型号由 Google 于 2024 年发布,有 2B 和 7B 尺寸可供选择。 2B 模型仅针对代码完成进行训练,7B 模型针对代码填充和自然语言提示进行训练。
在本文中,我将测试 7B 和 13B 模型,这些模型在 HuggingFace 上可用,并且可以以 GGUF 格式下载。我将运行一个与 OpenAI 兼容的本地服务器,这将允许我们将这些模型与不同的应用程序一起使用。但在此之前,我们先在 Python 中运行模型,看看它们能做什么。想要直接进入实际应用的读者可以跳过这一部分。
为了测试这两个模型,我将使用免费的 Google Colab 实例。首先,让我们加载模型和标记器:
从变压器导入AutoTokenizer、AutoModelForCausalLM、BitsAndBytesConfig
导入变压器
导入火炬
model_id = "..."
bnb_config = BitsAndBytesConfig(
load_in_4bit= True ,
bnb_4bit_quant_type= "nf4" ,
bnb_4bit_use_double_quant= False ,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM。 from_pretrained(
model_id,
quantization_config=bnb_config1,
device_map= "cuda" ,
torch_dtype=torch.bfloat16,
)
HuggingFace 的Transformers库非常智能,可以自动下载模型文件。 7B 模型需要大约 16.2 GB 的 GPU RAM,因此我在位和字节库的帮助下以 4 位分辨率运行该模型;之后,所需内存占用仅为 5 GB 左右。
现在,让我们创建一个代码片段来测试模型。作为示例,我创建了一个 Python 方法来将字符串列表写入文件:
python_code = """
class Writer:
def write_file(self, filename: str, data: List[str]):
\"\"\"
使用 open(filename, 'w') as f_out:
对于数据中的行:
f_out.write(f"{line}\n")
"""
为了测试模型的编码能力,让我们要求两个模型为其进行“pytest”:
chat = [{
"role" : "user" ,
"content" : f"为此 Python 方法编写一个 pytest:\n {python_code} . " \
f"在测试结束时删除创建的文件。"
}]
提示 = tokenizer.apply_chat_template(chat, tokenize= False , add_ Generation_prompt= True )
输入 = tokenizer.encode(prompt, add_special_tokens= False , return_tensors= "pt" )
输出 = model.generate(input_ids=inputs.to(model.设备), max_new_tokens= 1024)
结果 = tokenizer.decode(outputs[ 0 ])
至于结果,CodeLlama 7B生成了这段代码,生成时间为 19 秒:
import pytest
class TestWriter :
def test_write_file ( self ):
writer = Writer()
filename = 'test.txt'
data = [ 'line1' , 'line2' , 'line3' ]
writer.write_file(filename, data)
with open (filename , 'r' ) as f:
lines = f.readlines()
断言行 == data
os.remove(filename)
CodeGemma生成了这段代码,这个过程花了 16 秒:
import pytest
def test_write_file ():
""" 测试 write_file 方法 """
filename = "test.txt"
data = [ "This is a test" , "line 2" , "line 3" ]
Writer().write_file( filename, data)
with open (filename, "r" ) as f:
assert f.read() == "This is a test\nline 2\nline 3\n"
import os
os.remove(filename)
就我个人而言,我更喜欢第二个版本。首先,CodeGemma 提供了该方法的文档字符串描述,这是现代“linter”工具的要求。其次,与声明变量并稍后使用它Writer().write_file(...)相比,代码看起来更紧凑且更具可读性。writer第三,CodeGemma 导入了“os”Python 模块,而 CodeLlama“忘记”执行此操作。
乍一看,两个代码片段看起来都是正确的。让我们通过执行pytest -v file.py命令来运行代码:
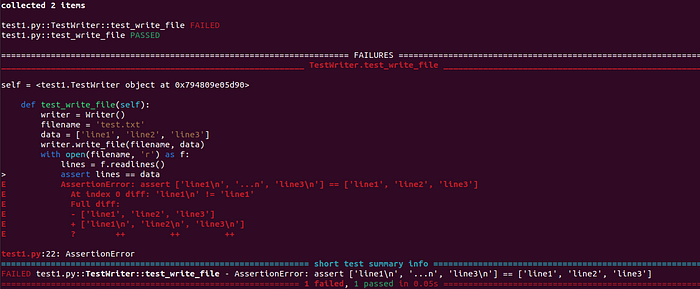
Pytest 结果,作者图片
事实上,我对两个测试的正确性都是错误的,第一个测试存在错误。有趣的是,第二个测试不仅看起来更好,而且也有效,而第一个则不行。从屏幕截图中可以明显看出该错误;欢迎读者自行找出解决方法。
最初,我并不打算测试CodeGemma 2B“代码完成”模型,但作为对读者的奖励,让我们测试一下吧!模型的加载是一样的;我们只需要更改模型ID:
model_id = "google/codegemma-2b" model = AutoModelForCausalLM.from_pretrained(model_id, ...)
该模型经过训练以完成代码。不需要任何英文描述,我们只需要提供源代码:
# 提示
python_code = """
class Writer:
def write_file(self, filename: str, data: List[str]):
...
import pytest
def test_write_file():
\"\"\"\ 测试 write_file 方法 \" \"\"\
"""
Prompt = f"""
<|fim_prefix|> {python_code}
<|fim_suffix|>
<|fim_middle|>
"""
# 运行推理
input = tokenizer(prompt, return_tensors= "pt" ) .to(model.device)
Prompt_len = 输入[ "input_ids" ].shape[- 1 ]
输出 = model.generate(**inputs, max_new_tokens= 256 )
print (tokenizer.decode(outputs[ 0 ][prompt_len:]) )
考虑到模型的尺寸很小,结果出奇的好。它生成了以下输出:
def test_write_file ():
""" 测试 write_file 方法 """
writer = Writer()
writer.write_file( "test_file.txt" , [ "Hello" , "World" ])
with open ( "test_file.txt" , " r" ) as f:
lines = f.readlines()
断言lines == [ "Hello
" , "World
" ]
正如我们所看到的,这段代码不能“开箱即用”,但逻辑看起来是正确的。所需的修复是正确格式化该assert行:
断言行 == [ "Hello\n" , "World\n" ]
之后,“pytest”就通过了。该模型在测试后也没有删除该文件,但我没有在提示中要求它。最后但并非最不重要的一点是,小模型的执行时间仅为 3.3 秒,比大模型快约 5 倍。
2. 运行 Llama 服务器
我们用 Python 测试了我们的模型;现在让我们运行一个本地 OpenAI 兼容服务器。我将使用Llama-cpp-python来实现这一点。这是一个不错的轻量级项目;我们可以使用单个命令行运行我们想要的任何模型:
# 代码 Gemma python3 -m llama_cpp.server --model codegemma-7b-it-Q4_K_M.gguf --n_ctx 8192 --n_gpu_layers - 1 --host 0.0 .0 .0 --port 8000 # 代码 Llama 7B python3 -m llama_cpp .server --model codellama-7b-instruct.Q4_K_M.gguf --n_ctx 8192 --n_gpu_layers - 1 --host 0.0 .0 .0 --port 8000 # 代码 Llama 13B python3 -m llama_cpp.server --model codellama- 13b-instruct.Q4_K_M.gguf --n_ctx 8192 --n_gpu_layers - 1 --主机0.0 .0 .0 --端口8000
如果没有足够的 GPU RAM 来加载模型,n_gpu_layers可以更改参数以仅将部分层加载到 GPU 中。我们也可以在 Apple Silicon 甚至 CPU 上运行模型,但显然会慢一些。
3. 应用程序
目前,我们有一个本地 OpenAI 兼容服务器,我们已经准备好测试一些应用程序了!
3.1 AI外壳
AI Shell是一款开源应用程序,可以将自然语言提示转换为控制台命令。这个应用程序非常受欢迎,在撰写本文时,该项目在 GitHub 上有 3.6K 颗星。 AI Shell 是用 TypeScript 编写的,我们可以通过npm包管理器安装该应用程序(这里我还安装了 Node JS 20.13.0):
卷曲 -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash nvm install v20.13.0 npm install -g @builder.io/ai-shell
在运行应用程序之前,我们需要配置API端点:
ai 配置集OPENAI_KEY=12345678 ai 配置集OPENAI_API_ENDPOINT=http://127.0.0.1:8000/v1
现在,我们可以随时通过在控制台中输入“ai chat”命令来与模型开始对话:

AI Shell 终端输出,图片由作者提供
使用程序的另一种方法是输入我们要执行的命令。例如,我们可以输入类似“显示当前文件夹中的文件”的内容:
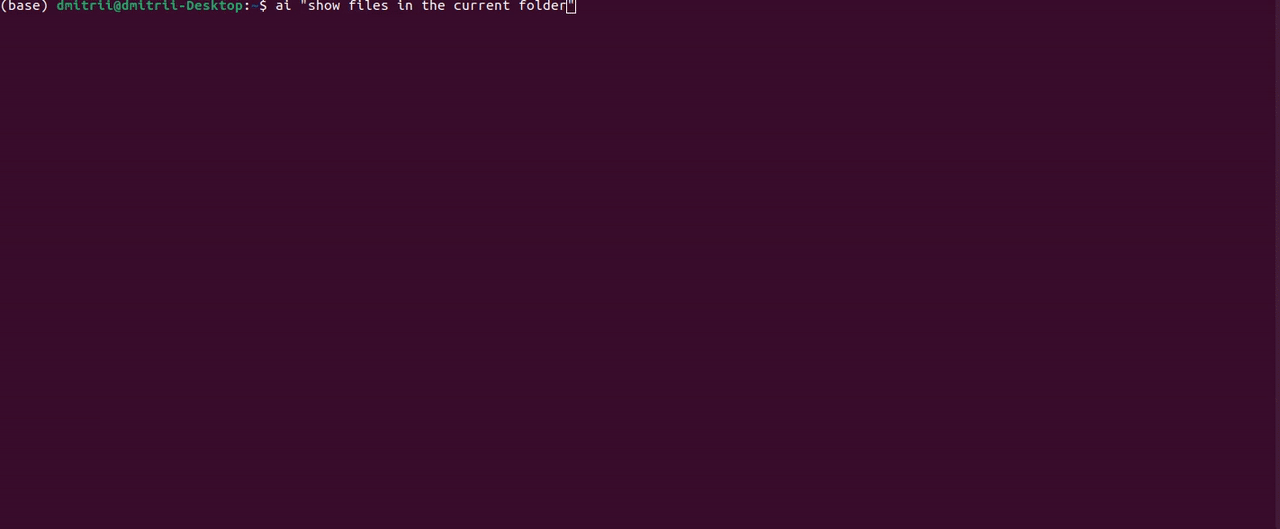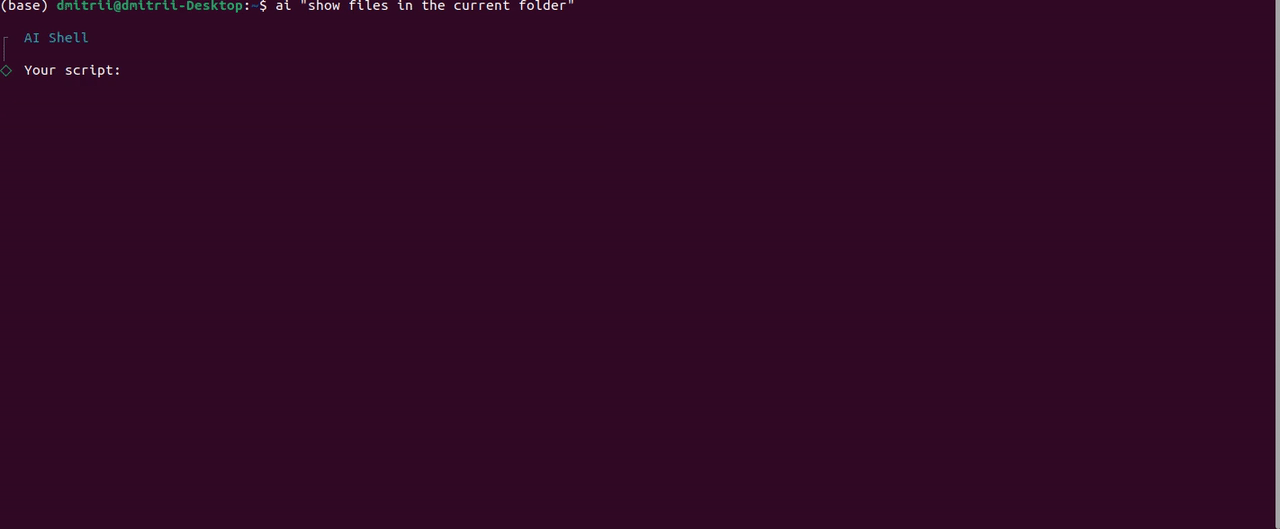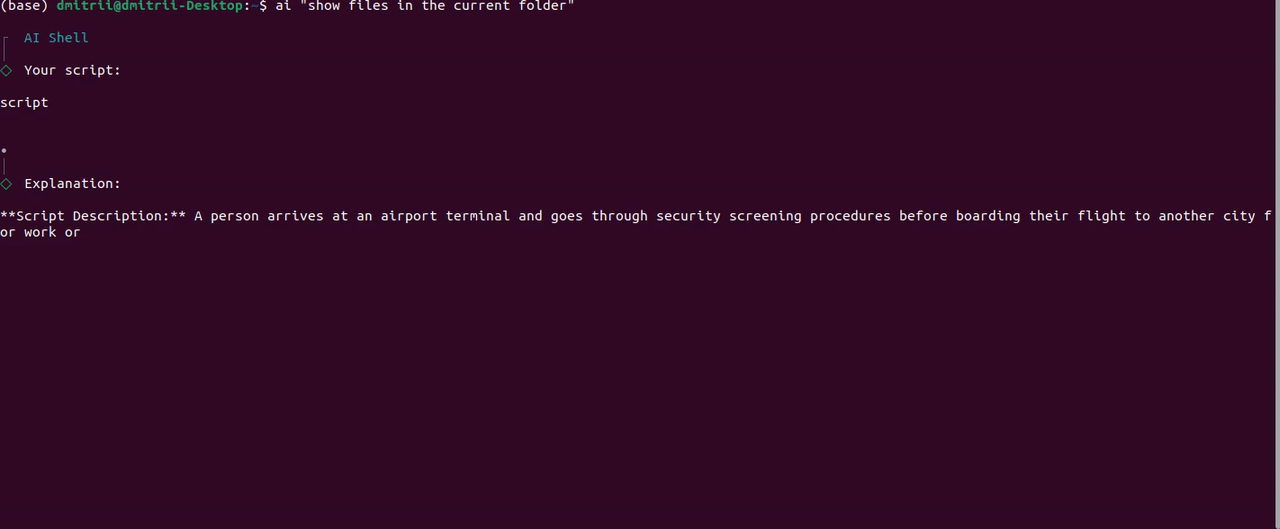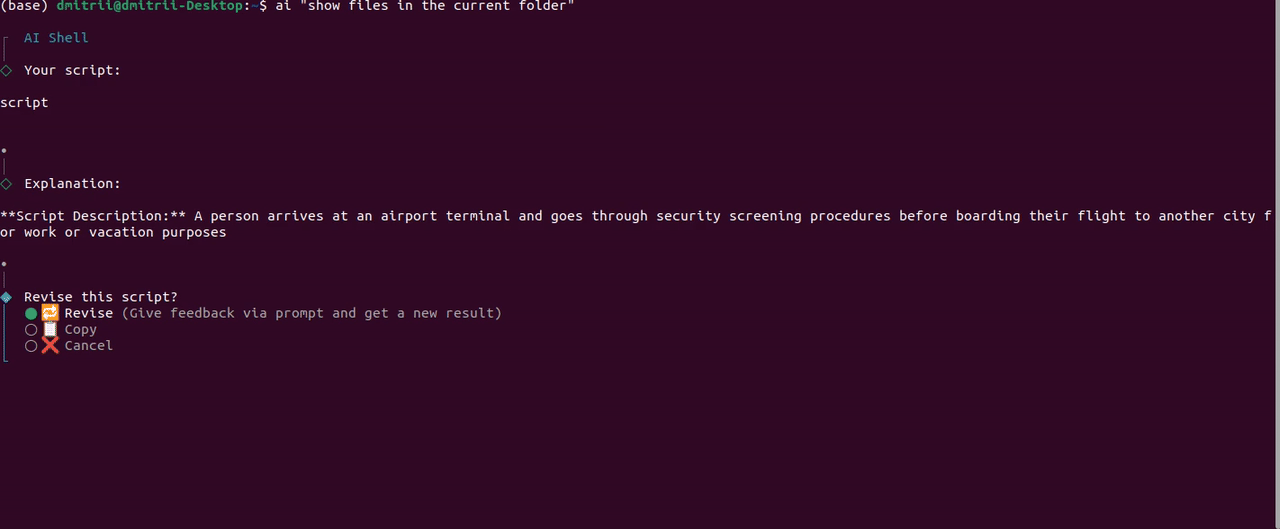
AI Shell 终端输出,图片由作者提供
唉,使用免费的 7B 模型,它不起作用,并且该模型无法生成正确的 shell 命令。此外,提示中的“脚本”一词显然混淆了模型,它生成了有关电影脚本的文本。
这个问题可能可以通过调整提示来解决,但在编写本文时,提示已硬编码在 TypeScript 源中,无法轻松配置。目前还没有人回复我在 GitHub 上的功能建议,但希望将来会得到改进。
3.2 ShellGPT
ShellGPT是另一个有趣的开源项目,在撰写本文时,它在 GitHub 上拥有 8.3K 颗星。我们可以使用pip轻松安装应用程序:
pip3 安装 shell-gpt
要将 ShellGPT 与本地模型一起使用,我们需要更改~/.config/shell_gpt/.sgptrc文件中的 API 端点:
API_BASE_URL =http: //127.0 . 0.1:8000 /v1 OPENAI_API_KEY = 12345678
然后我们可以直接在终端 shell 中输入我们的请求,几乎与之前的应用程序相同:
sgpt “编写命令来显示本地文件”
唉,CodeGemma模型无法与 ShellGPT 一起使用,并且 LlamaCpp 服务器返回服务器 500 错误:“系统角色不受支持”。起初,我以为这是 LlamaCpp 的问题,但在查看日志后,我发现模型元数据有以下几行:
{% if messages[0][ 'role' ] == 'system' %}
{{ raise_exception( '不支持系统角色' )
遗憾的是,CodeGemma 不支持“系统”角色,因为它在 OpenAI API 中被广泛使用。因此,兼容 OpenAI 的应用程序无法使用 CodeGemma,这很遗憾,因为正如我们之前看到的,CodeGemma 生成的代码非常好。
至于CodeLlama,ShellGPT 效果很好:
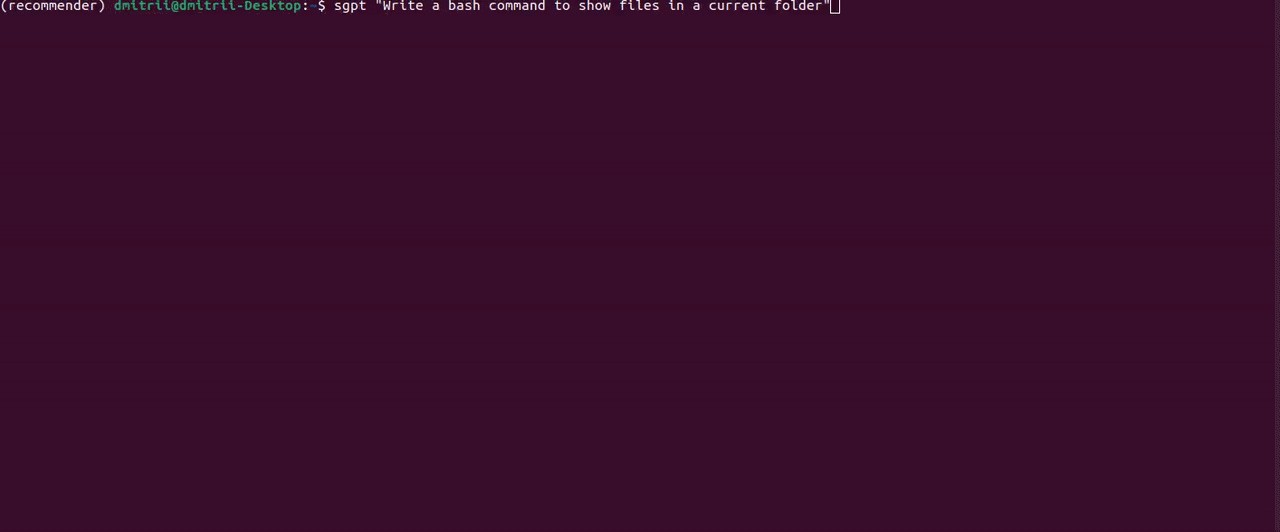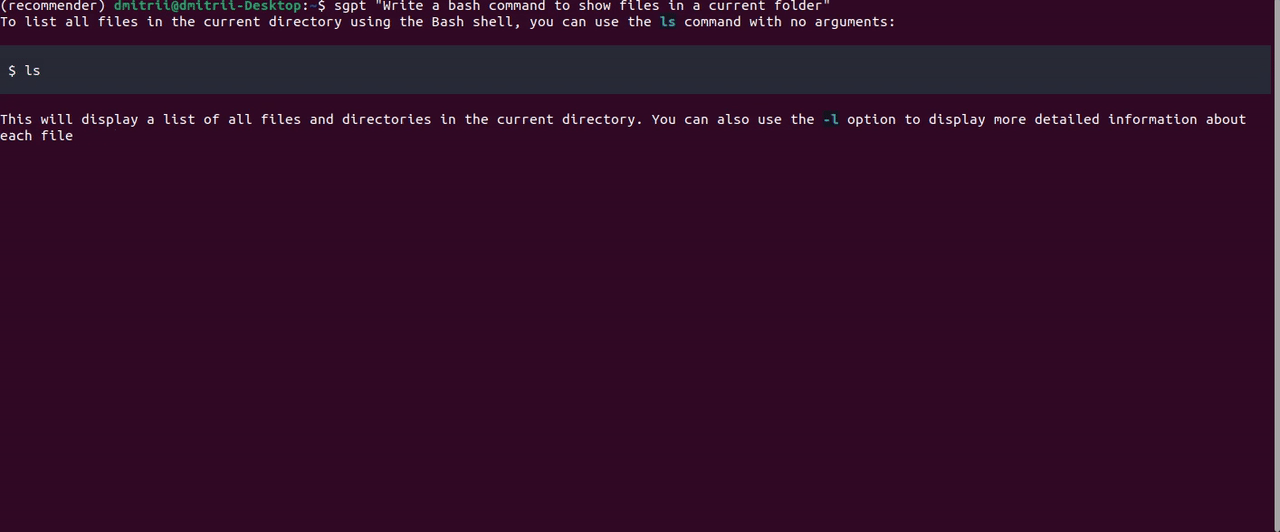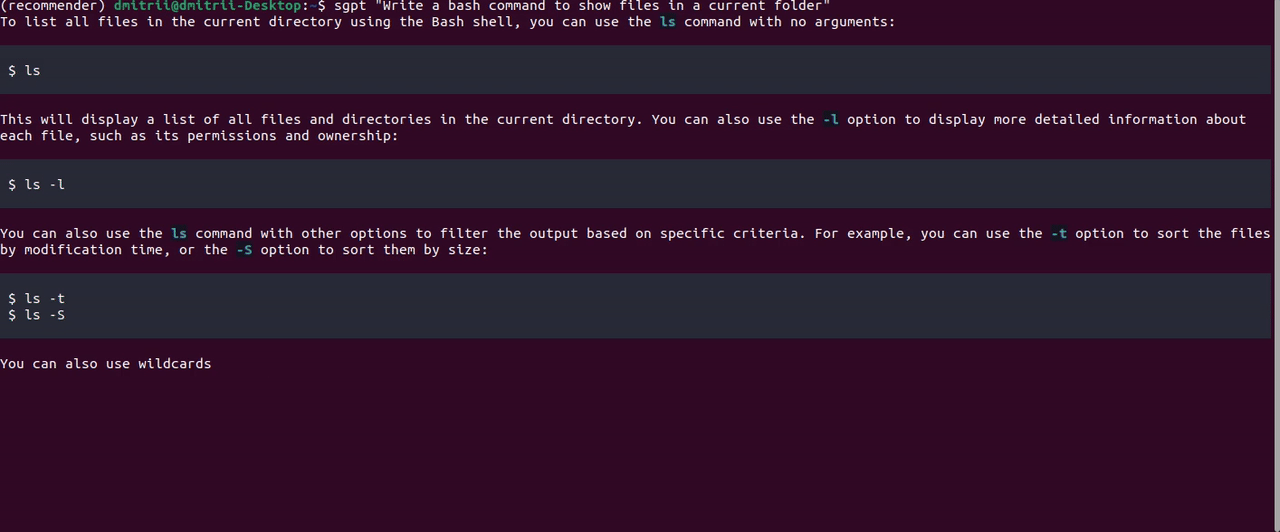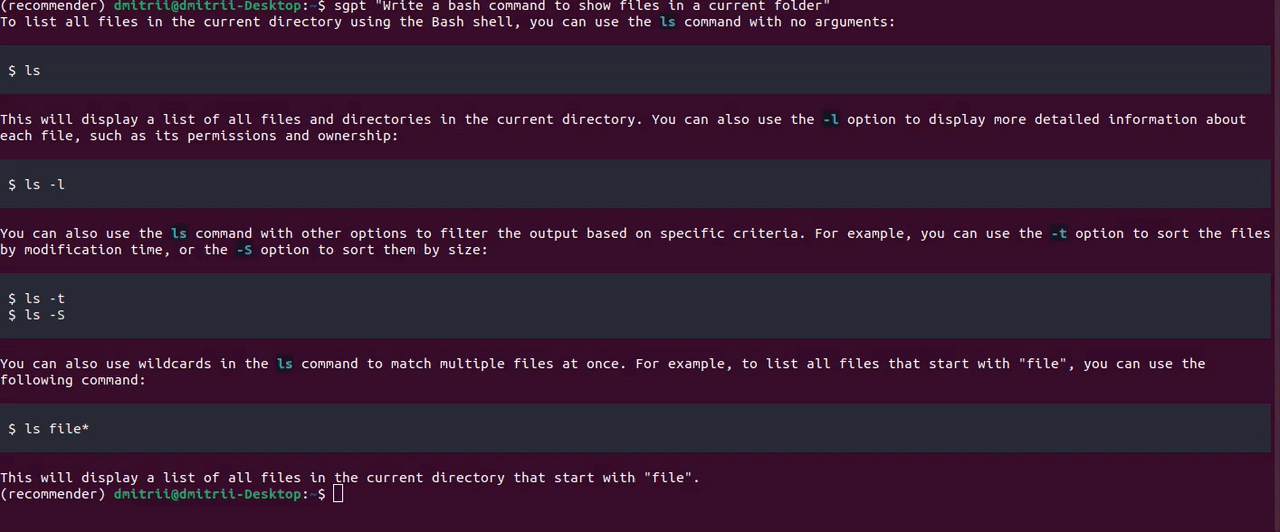
另一个有用的功能是通过指定前缀直接在终端 shell 中执行命令--shell:
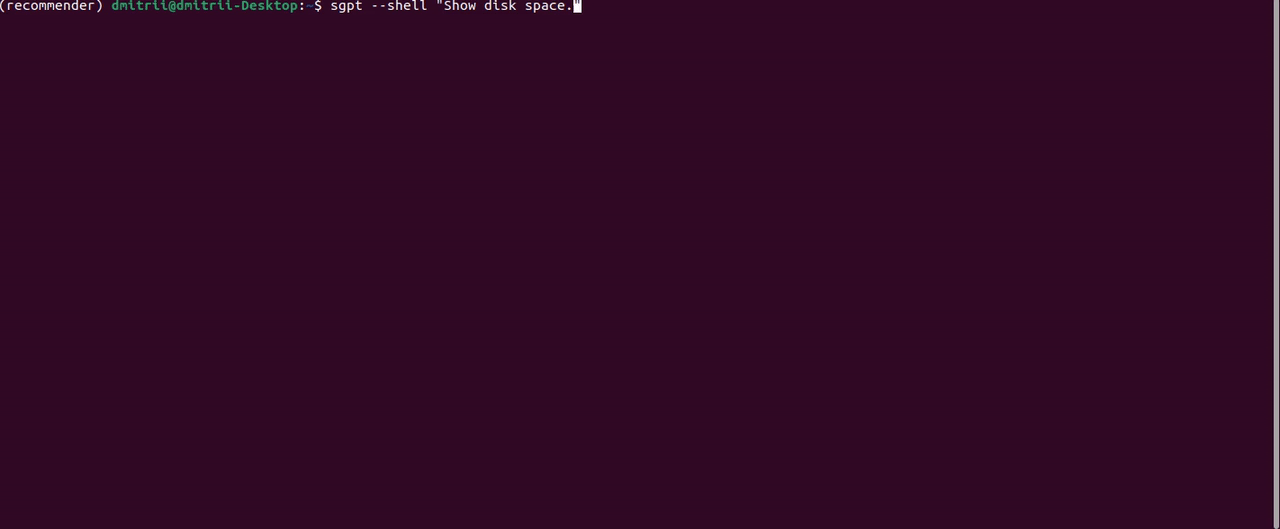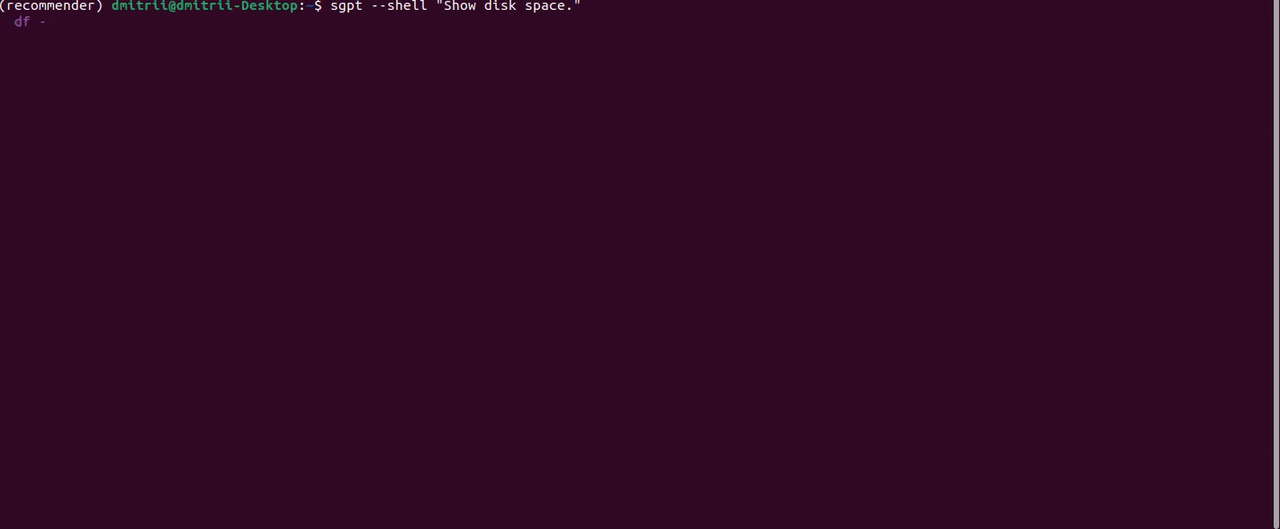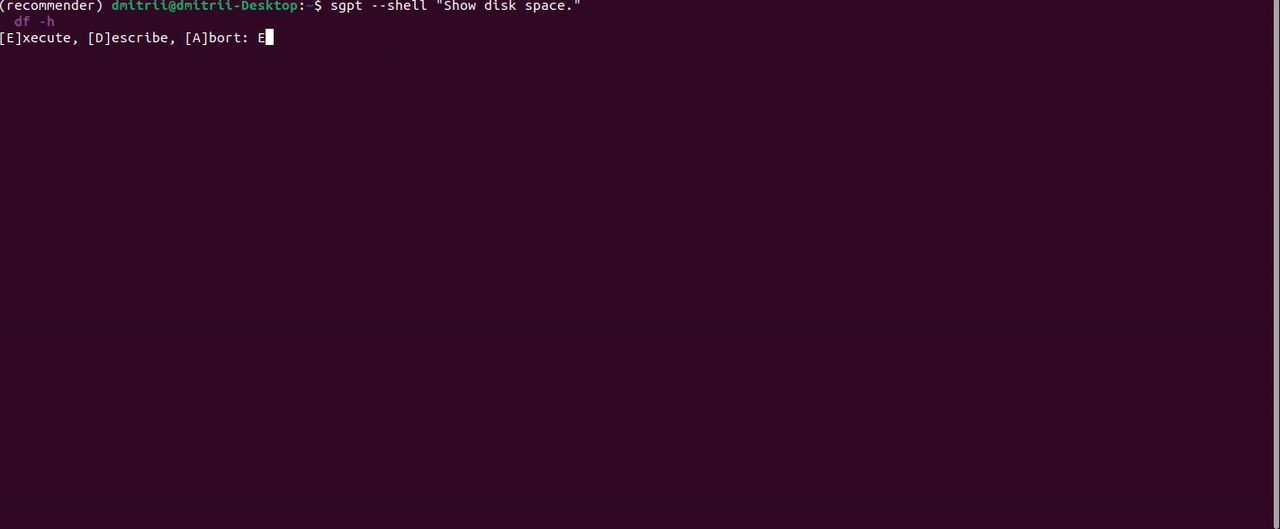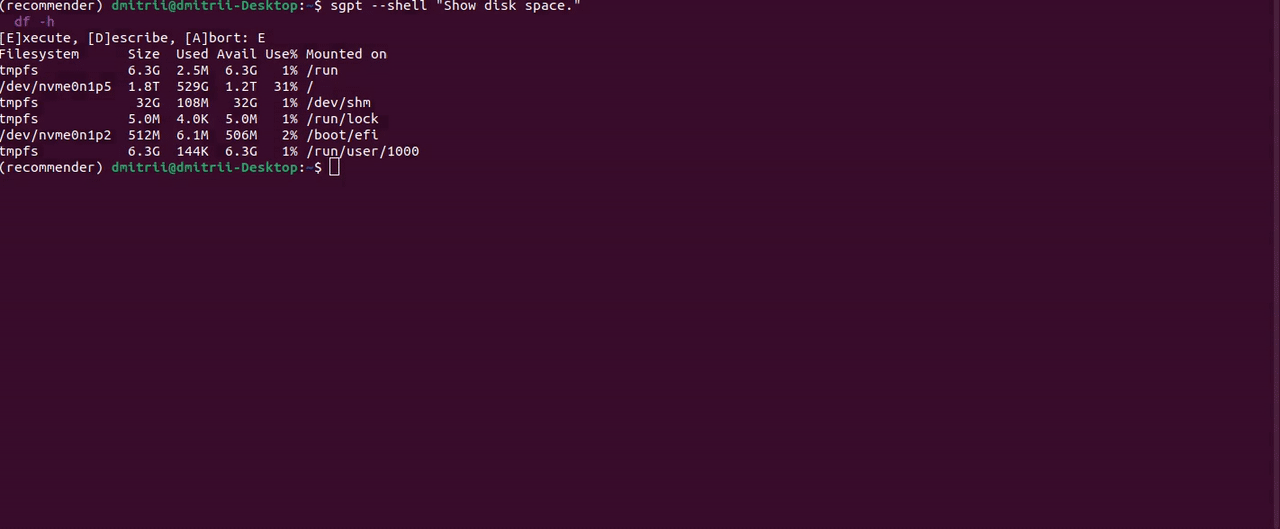
有改进的余地;例如,“显示文档文件夹的大小”提示返回响应```du -sh ~/Documents```。这是一个正确的 bash 命令,但 ShellGPT 无法从字符串中获取它```,所以我只得到一个command not found错误。
3.3 代码GPT
使用 bash 命令可能很有用,但是实际的编码帮助怎么样?我们可以借助开源CodeGPT插件来做到这一点。首先,我在 PyCharm IDE 中安装了该插件并将其配置为与 LlamaCpp 一起使用:
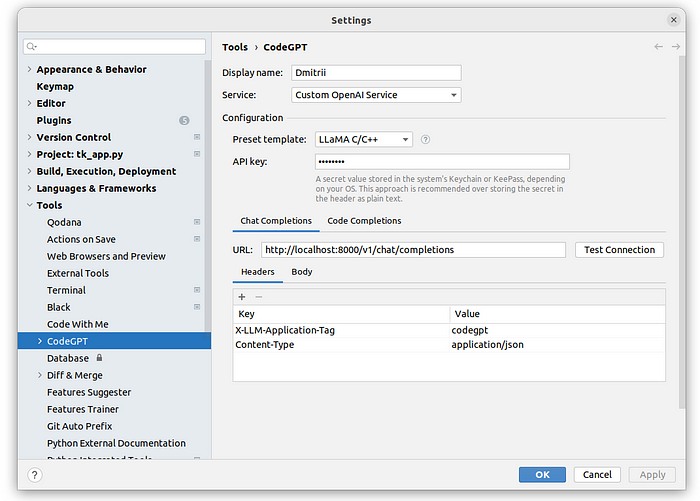
CodeGPT 设置,作者提供的图片
作为示例,让我们考虑这个 Python 类:
class ServerConnection :
""" 服务器连接处理 """
def __init__ ( self ):
self.is_connected = False
self.connection_time = - 1
self.uploads_total = 0
self.reconnects_total = 0
self.reconnect_threshold_sec = 64
我将要求模型将变量重构为单独的Python 数据类。
至于结果,CodeGemma做不到;它返回错误“不支持系统角色”。CodeLlama 7B未能完成任务;它创建了一个标准类而不是数据类。CodeLlama 13B很好地完成了任务:
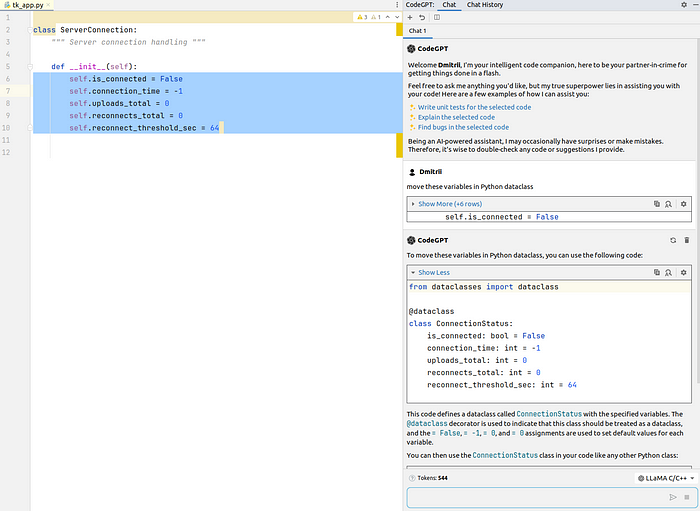
CodeGPT 聊天,图片由作者提供
下一步,我决定问一些更复杂的问题并输入create a UI Python application with a textfield and button提示。 Llama 13B 模型生成了以下代码:
import tkinter as tk # 创建主窗口 root = tk.Tk() root.title( "My Application" ) # 创建文本字段 text_field = tk.Entry(root) text_field.pack() # 创建按钮 Button = tk .Button(root, text= "Click Me!" , command= lambda : print ( "You clicked the button!" )) button.pack() # 启动主循环 root.mainloop()
代码是正确的,但应用程序窗口不可见 – 未指定其大小。我继续聊天,要求模型将标题更改为“Hello World”,并将窗口大小设置为 320×200:
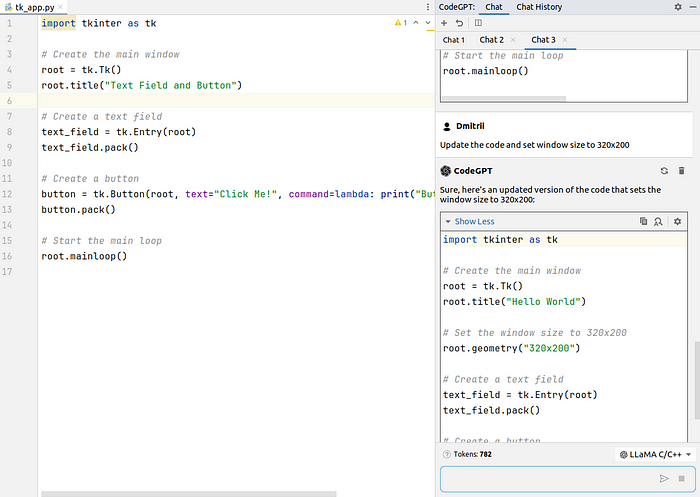
CodeGPT 聊天,图片由作者提供
现在,结果很好,请求的应用程序按预期工作:
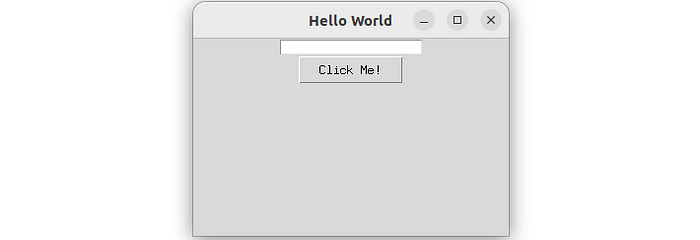
Tkinter 应用程序,作者提供的图片
我必须承认 13B 模型并不完美。理论上,它有一个很大的上下文窗口,应该使用以前的聊天结果,但当我要求模型将生成的代码移到一个类中时,它生成了一个新代码,而没有设置窗口大小或标题:
import tkinter as tk
class HelloWorld (tk.Frame):
def __init__ ( self, master= None ):
super ().__init__(master)
self.pack()
# 创建文本字段
self.text_field = tk.Entry(self)
self.text_field.pack()
# 创建一个按钮
self.button = tk.Button(self, text= "Click Me!" , command= lambda : print ( "Button clicked!" ))
self.button.pack()
if __name__ == "__main__" :
root = tk.Tk()
app = HelloWorld(root)
root.mainloop()
但总的来说,模型创建了一个正确的类,并且通过一些复制粘贴,很容易完成工作。
4、缺点
从最后的所有例子中,我们可以看到该模型是有效的;它可以生成代码和 bash 命令。但也存在一些缺点和问题:
- 使用本地 LLM 实例需要良好的显卡。我有一张使用了 2.5 年的 GeForce RTX 3060 卡,具有 8GB GPU RAM。在我的 Colab 测试中,我发现 8 GB 足以运行 7B 模型,但在真实的桌面上,没有足够的 CUDA 内存来运行——操作系统本身也需要一些 GPU 才能工作。实际上,要运行 13B 模型,至少需要 16 GB GPU RAM,建议使用 24 GB,以便为将来的改进留出一些空间。有实际意义吗?考虑到当前的 GPU 价格,我不能 100% 确定——只需花费 1000-1500 美元,我们就可以订阅 AI 多年。
- 开源应用程序并不完美。在我的测试中,LlamaCpp 服务器有时会因“分段错误”而崩溃,CodeGPT 应用程序有时不会向模型发送任何请求,我不得不重新启动 PyCharm,等等。它是开源的,没有任何形式的保证,所以我不是在抱怨,但我必须承认,对于这些人工智能工具,我们正处于“早期采用”阶段。
- 有趣的是,运行大型本地语言模型是一项耗能的任务。作为最后一次测试,我将功率计连接到我的台式电脑。事实证明,正常工作时,其功耗约为80瓦。但是当LLM请求运行时,能耗几乎增加了三倍:

AI模型请求期间的功耗,作者提供的图片
结论
在本文中,我测试了开放语言模型作为编码助手的能力,结果很有趣:
- 即使小型 7B 和 13B 模型也可以执行一些编码任务,例如重构、进行单元测试或编写小型代码模板。显然,与 175B ChatGPT 3.5 等大型模型相比,这些模型的能力较差,但使用本地模型不需要任何订阅费用;从隐私角度来看,它也可以更快更好。
- 另一方面,运行本地模型需要高端硬件,这不仅昂贵而且耗能。在撰写本文时,高端 GPU 的成本可能高达 1500 美元,这对于仅运行本地 LLM 来说是不切实际的 – 对于这个成本,我们可以订阅云服务很长一段时间。
- 使用人工智能工具的挑战不仅在于硬件,还在于软件。至少在撰写本文时,人工智能软件的开源生态系统尚未成熟。我惊讶地发现,HuggingFace 上有 39,769 个开放的 7B 模型,但 GitHub 上的开源 AI 应用数量却少之又少。本文中描述的这三个几乎是我能找到的全部(如果我遗漏了什么,请在下面的评论中写下,也许我会做第二部分的评论)。
一般来说,使用本地法学硕士来完成日常编码任务是可行的,但正如我们所看到的,在软件和硬件方面仍然存在许多挑战。我们也知道,现在不同的公司很难致力于更高效的人工智能芯片和更高效的模型。像微软的 Phi-3这样的新模型甚至能够在移动硬件上运行。它将如何改变AI行业?下一代集成显卡会便宜、安静、兼容 CUDA 吗?我们还不知道。显然,将会发布很多新的人工智能相关硬件(M4已经是第一个),至少我希望新硬件不会是专有的,没有任何开放使用的驱动程序。
