




本周,Stability AI宣布推出Stable Diffusion 3 (SD3),这是最著名的图像生成开源模型的下一代版本。
它在保真度和分辨率方面显示出令人惊叹的结果,无论从视觉上还是定量上来说,都使其成为当今业界最好的文本到图像 (T2I) 模型。
更重要的是,它最终解决了AI图像中最难的问题之一——文图对齐。
但是,以我的拙见,这对于人工智能来说是一个特别特殊的时刻,因为它带来了几种创新方法,既有继承的,也有全新的,可以将其架构设定为图像合成的新标准。
掌握流程
如果我们考虑一个生成模型,无论是ChatGPT还是SD3,都有一个共同的原则;他们都学习训练数据的基本分布,以便从中进行采样。
但这到底意味着什么呢?
都是模式学习
如果我们考虑 ChatGPT,当我们说它学习训练数据分布时,我们间接地说该模型学习训练语料库的模式和结构。
用外行的话来说,它学习单词如何相互跟随。
像 SD3 这样的 T2I 模型在这个意义上没有什么不同,只是学习训练图像的分布。简而言之,他们学到了诸如“如果我看到一组描绘狗脸的像素,那么身体的其余部分一定在附近”之类的东西。
然而,需要注意的是,T2I 主要是流扩散模型,这意味着它们不仅学习训练数据的分布,而且还学习实时地将随机分布中的点提取到目标分布中。
我知道这是一个艰难的吞咽,所以让我们简化这个概念。下图展示了流模型的初始状态,其中我们有一个纯随机分布p(x)(由于像素是随机分布的,这本质上是噪声)。
我们不知道目标分布q(x)是什么,但我们知道该分布中的许多样本(以红色表示),它们代表我们的训练数据。
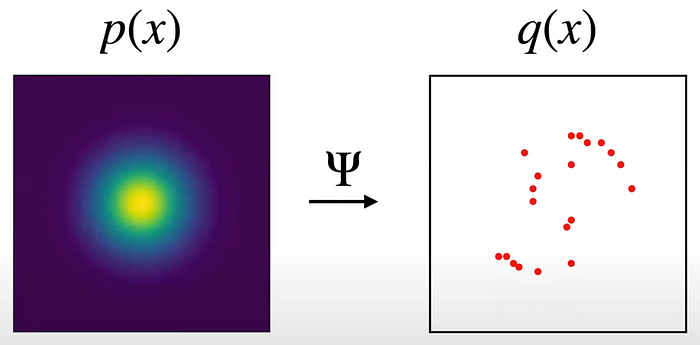
如前所述,我们的目标是找到q(x),以便模型可以有效地生成属于该分布(也称为训练数据的分布)一部分的新图像。
因此,任何流模型(无论是稳定扩散 3 还是 DALL-E)的训练过程都将如下所示,模型本身描述为τ:
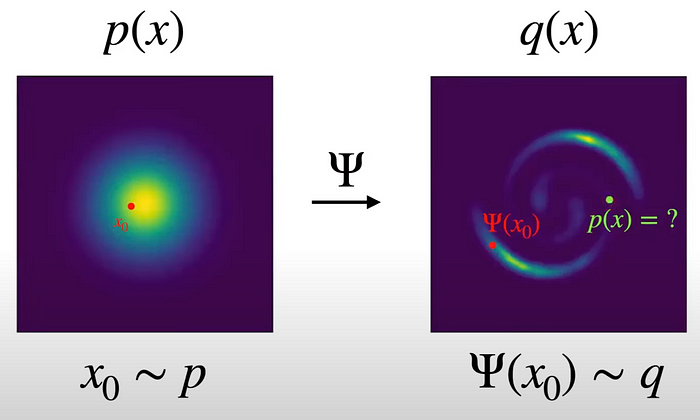
如果仔细观察,您会发现新分布的形状与我们训练数据最初的分布方式相匹配。
如果您训练一个模型来有效地执行此转换,瞧,您就得到了一个流模型,该模型采用像x0这样的点并将它们转换为落在q(x) 分布内的点(例如,您的新图像)。
这些流也经过调节,以便您可以实际指示需要生成的内容。
由于q(x)基于高质量的训练数据,我们知道生成的新图像将与训练期间观察到的图像相似,正如前面提到的,这一直是任何生成模型的目标。
但为什么我们首先需要流量模型呢?
流程生成模型
最重要的是,Flow 模型学习一种“映射”,它将采用嘈杂的随机“画布”并将其转换为与训练期间看到的其他图像相似的图像,同时以用户的请求为条件来驱动图像生成过程。
这样,它就可以画出“打篮球的动物”之类的东西:
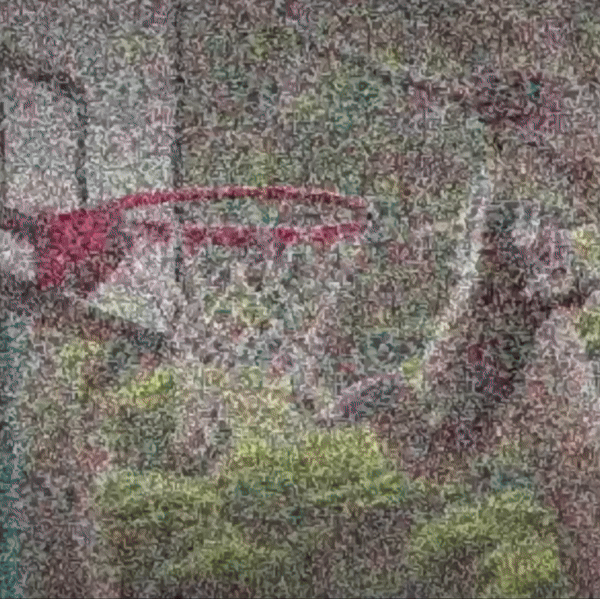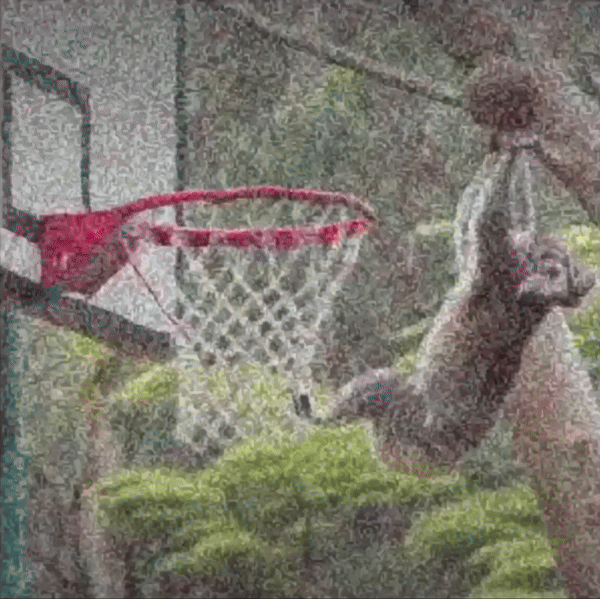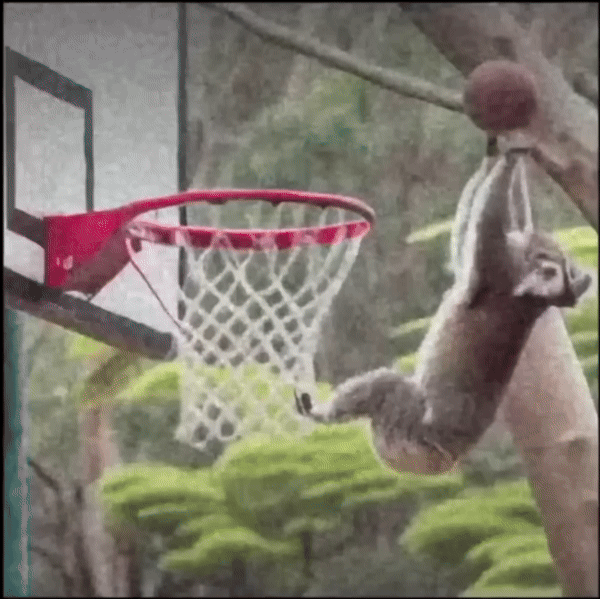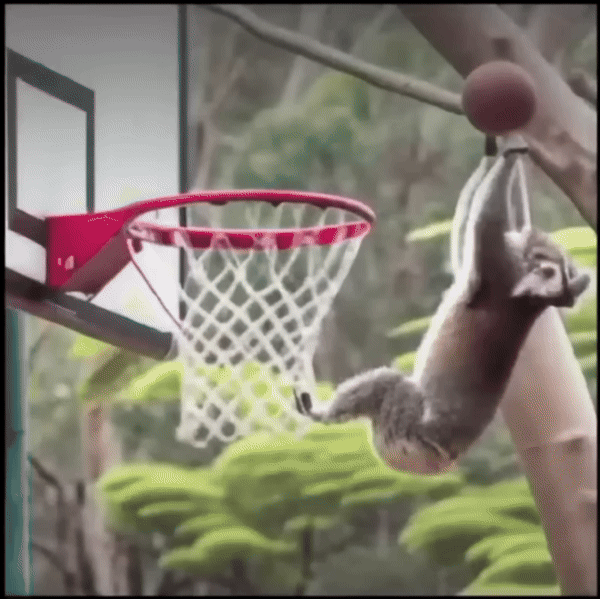
来源:OpenAI
但为什么我们需要这个流程,而不是像我们使用 ChatGPT 处理文本一样从学习到的图像分布中进行采样?
好吧,您希望您的模型具有某种随机性或随机性,以便新生成的样本是新图像,而不仅仅是训练期间看到的图像的副本。
就 ChatGPT 而言,在采样过程中添加了随机性,因为与普遍看法相反,ChatGPT 并不总是为您提供“最可能准确的单词”。
大多数时候,它会随机选择“从‘k’个最可能准确的单词中选择一个”。实际上,您可以使用温度变量(LLM API 的一个属性)来“控制”此过程。
回到扩散模型,这种总是偏离随机画布的映射使得模型能够根据一个提示(例如“狒狒特写”)生成多个不同的图像。

来源:OpenAI
然而,这里 SD3 通过应用整流流进行了相当大的创新,其中不同分布中的点之间的流动是沿直线完成的,这与大多数扩散模型使用的标准曲线不同。
简而言之,分布之间的传播距离越短,采样速度就越高。
换句话说,图像的生成速度要快得多,考虑到Dall-E或MidJourney等模型的速度有多慢,这是一个很大的进步。
但是等等,简单来说,扩散背后的关键直觉是什么?
我始终将扩散过程视为大理石雕塑的数字版本。
像米开朗基罗或贝尔尼尼这样的艺术家会拿一块大理石,慢慢地擦除多余的大理石,首先创造出粗糙的图形,然后最终完善形状。
扩散也是类似的,你有一堆垃圾,然后你慢慢地“发现”真正的部分。
“在我开始工作之前,雕塑已经在大理石块内完成了。它已经在那里了,我只需要把多余的材料凿掉就可以了。”
— 米开朗基罗
长话短说,用外行人的话来说,将流扩散模型视为神经网络,通过应用图像生成过程中实时进行流变换。
如需更多技术深度,我建议您观看以下由 Meta 的 Yaron Lipman 解释的视频。
接下来,SD3 还采用了扩散变压器的概念,放弃了黄金标准 U-Net。
这是一件大事,因为 OpenAI 也对Sora做了同样的事情(事实上,Sora 的主要创造者William Peebles也恰好是扩散变压器的创造者)。
随之而来的是,一个新的标准诞生了。
DiT 和体重专业化
首先,SD3 架构再次证明注意力仍然是王道。
关注就是你所需要的
扩散变压器是一种将扩散(我们刚刚介绍的概念)与变压器(ChatGPT 或 Gemini 等模型背后的架构)相结合的设计。
原因是变形金刚的主要组成部分,即注意力机制,对于图像和文本都同样有效。
那么,变形金刚在哪里符合扩散概念呢?
在这种情况下,它是一种允许输入数据的不同部分共享信息的机制,以便模型建立对其所观察到的内容的理解。
通俗地说,注意力就是模型如何学习数据的分布。
尽管如此,SD3 研究人员还是添加了一些变化。
重量并不意味着共享
当使用处理文本和图像的模型时(您用文本发送所需内容的请求,但生成的输出是图像),模型的参数需要处理非常复杂和不同的模式。
其主要原因是文本和图像是截然不同的数据结构。因此,就像大脑有专门处理文本和图像的不同区域一样,研究人员为每种模式定义了特定的权重。
当然,您最终会在注意力过程中交叉两组权重,以确保文本和图像权重共享信息,就像大脑中的不同区域也进行通信一样。
这会产生壮观的图像,如下图所示:
请注意果酱如何与水混合,这可能意味着该模型具有一些世界知识。

接下来,真正的问题是:它与其他模型相比如何?
开源依然活跃
与当前最先进的测量颜色、位置和其他客观 KPI 的GenEval基准相比, SD3 超越了所有以前的模型,并且在人类评估中也发生了同样的情况(这更加主观,必须与少许盐一起服用)。

举个例子,这些模型很快就会公开,参数范围从 8 亿到 80 亿。
因此,只要有足够强大的电脑桌面,您很快就可以免费运行SD3家族的任何型号。
免责声明: 2B 型号至少需要 8GB RAM(最好是 16 GB),较大型号则需要 24GB。
对于较小的型号,大多数 iPhone 都可以毫无问题地运行。
最后一点,SD3 的成员们还有最后一个惊喜。
DPO 继续展现出惊人的成果
SD3 再次证实了直接偏好优化(DPO)的工作原理。
简单来说,DPO 允许模型针对给定的人类偏好进行优化,通常表示为:
- (提示,更好的答案,更差的答案)
这样,该模型就可以学习如何通过自然地倾向于输出与人类选择的“更好”的图像相似的图像,来最大限度地实现给定的人类愿望的效用(和安全性)。
正如我们在下面所观察到的,SD3 案例中的结果简直令人惊叹,因为 DPO 后的结果(第二行和第四行)与非 DPO 对应结果(第一行和第三行)相比令人惊讶。

成为开源支持者的美好一天
总而言之,SD3 是一个伟大的模型,也是 Stability AI 对开源领域的巨大贡献。
他们不仅成功地创造了一种新的最先进的技术,而且还通过创新和免费分发所有这些宝贵的信息来做到这一点。
虽然开源在文本领域可能落后,但在图像生成方面却处于领先地位。
