




OpenAI 对人工智能行业的影响力怎么强调都不为过。每一个举动或决定都会自动成为头条新闻……即使他们实际上并没有宣布这件事。
几天前,我们很多人都在玩的一个模型后来被删除,让整个人工智能行业着迷。它被命名为“gpt2-chatbot”,可以在lmsys.org的“直接聊天”功能中访问几天。
但为什么这么大惊小怪呢?
嗯,因为这个模型与我们见过的任何模型都不一样。这是完全不同的水平。
因此,许多人认为它是ChatGPT-4.5甚至GPT-5的非官方预告片。或者,更令人兴奋的是,使用数字“2”作为新 GPT 一代长推理模型即将到来的信号。
就连 OpenAI 的首席执行官 Sam Altman 也无法抗拒诱惑,承认它的存在,并在此过程中取笑我们:
那么,这个模型有多好,它到底是什么?
您可能已经厌倦了谈论这个或那个**如何**发生的人工智能时事通讯。这些时事通讯比比皆是,因为粗略地谈论已经发生的事件和事情很容易,但提供的价值有限,而且炒作被夸大了。
然而,谈论即将发生的事情的时事通讯却很少见。如果您想先于其他人对人工智能的未来进行易于理解的见解,那么TheTechOasis时事通讯可能非常适合您。
🏝️🏝️ 今天订阅如下:
科技绿洲
即将发生的事情的预告片
随着时间的推移,很明显 OpenAI 的下一个模型将在推理和复杂问题解决方面实现飞跃。
为了证明这个新的神秘模型可能是怎样的,这里只是这个神秘模型的威力的几个例子,它可以表明该船已经降落在那个港口:
对于当前最先进的模型来说,下面的所有示例都被认为是困难或完全不可能的。
对于初学者来说,它以零样本模式解决了数学奥林匹克问题(没有提供辅助示例来支持解决方案):

我什至无法开始解释前面的例子有多么疯狂,从当前最先进的模型中绝对不可能得到这样的答案。
它在解析 JSON 方面也绝对出色,这是 LLM 与 API 和其他基于 Web 的工具集成的基本技能。
此外,它在复杂的绘图任务上完全抹杀了 GPT-4,例如基于代码绘制 SVG 文件或使用 ASCII 代码绘制独角兽(如下),在这个过程中羞辱了当前最先进的Claude 3 Opus :
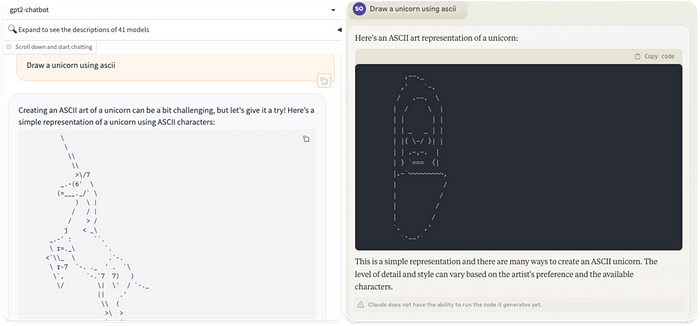
gpt2-chatbot(左)和 Claude 3 Opus(右)
此外,虽然这很可能是幻觉,但该模型向我声称它是由 OpenAI 训练的并且基于 GPT-4 变体。
当然,在展示了如此强大的功能之后,许多人认为“gpt2-chatbot”甚至可能是著名的 Q* 模型。
但是,我们不要简单地屈服于人们声称的各种奇特的选择,而是采取更明智的方法,看看 OpenAI 本身在几个月(甚至几年)的研究中暗示了什么。
长推理的力量
几个月来,Demis Hassabis或Andrej Karpathy等该领域的专家一直在讨论,光靠法学硕士是不够的,我们需要“其他东西”才能真正将他们带入下一步。
在这两种情况下,他们都指的是实现“AlphaGo,但在法学硕士”的同等地位,这间接指的是:
- 自我完善和
- 测试时计算法学硕士
但这是什么意思呢?
人工智能的一大进步
AlphaGo 是人工智能的历史。这是韩国棋盘游戏围棋中第一个明显超越人类力量的模型。
它使用蒙特卡洛树搜索(一种搜索算法)来探索游戏中任何给定步骤的可能动作范围,能够超越当前动作并预测对方玩家会做什么。
你们中有些人可能还记得“深蓝”,这台国际象棋机器在 1997 年输掉第一场比赛后,在系列赛的第二场比赛中勉强击败了加里·卡斯帕罗夫。
然而,虽然深蓝可以被击败,但AlphaGo却是无敌的。
但如何呢?
自我完善,成为超人
AlphaGo 之所以优越的关键因素在于它的训练方式,即通过与自身的较小版本对弈来创建自我改进循环。
它不断地与自己对弈,逐渐将 ELO 提高到 3.739,几乎达到了当今最好的围棋棋手的水平。
2017年,改进版AlphaZero达到了5.018 ELO,完全超人、无人能敌。
换句话说,借助AlphaGo,人类第一次实现了一种通过自我改进来训练模型的方法,使其不再依赖模仿人类来学习,从而获得超人的能力。
如果您想知道,法学硕士的情况并非如此。
目前的法学硕士完全与人类水平的表现挂钩,因为所有数据和培训本质上都依赖于人类(以至于调整阶段,即训练过程的一部分,法学硕士被建模以提高其安全水平并避免攻击性反应,严格使用“人类偏好”来执行)。
顺便说一句,Meta 最近提出了自我奖励模型,可以通过自己的反应进行自我改进。然而,目前还不清楚这种反馈循环是否真的能让法学硕士变得超人。
但尽管仍然很难相信“gpt2-chatbot”是通过自我改进进行训练的,但我们有足够的理由相信这是 OpenAI 多年来一直致力于的项目的首次成功实现:测试时计算。
测试时计算模型的到来
多年来,OpenAI 的几篇研究论文都暗示了将模型倾斜为“重推理”的想法。
例如,早在 2021 年,他们就提出了在推理时使用“验证器”的概念,以改善模型在处理数学时的响应。
这个想法是训练一个辅助模型,该模型将实时评估模型给出的多个响应,选择最好的一个(然后提供给用户)。
再结合某种树搜索算法(例如 AlphaGo 使用的算法)以及 Google Deepmind 的LLM思想树研究等示例,您最终可以创建一个 LLM,在回答之前探索“可能的响应领域” ‘,仔细过滤并选择解决方案的最佳路径。
一个思想树的例子
尽管 OpenAI 早在 2021 年就提出了这个想法,但如今已经非常流行,微软和谷歌的交叉研究将其应用于训练下一代验证器,谷歌甚至设法创建了一个模型Alphacode,该模型执行这种架构取得了巨大的成功,在有竞争力的程序员中达到了 85% 的百分位数,他们是这方面最优秀的人。
为什么新一代的法学硕士有如此大的潜力?
嗯,因为他们解决问题的方式与人类非常相似,通过深思熟虑和广泛的思考来解决给定的任务。
最重要的是,将“搜索+LLM”模型视为人工智能系统,它为模型的实际运行时间分配更高程度的计算(类似于人类思维),这样,它们就不必立即猜测正确的解决方案,而是简而言之,“给予更多时间思考”。
但 OpenAI 走得更远。
用于改进数学执行的 PRM 模型
早在去年 5 月,他们就发布了《让我们一步步验证》论文,OpenAI 首席科学家 Ilya Sutskever 本人以及原始验证论文的一些研究人员(例如 Karl Cobbe)也参与其中。
这里的想法是修改模型对齐阶段使用的奖励模型。
尽管我建议查看本文以获取有关 LLM 培训的完整指南,但创建 ChatGPT 等产品过程中的最后一步是使用人类反馈强化学习 (RLHF)。
这个想法是为了让模型改进其决策。因此,我们训练一个辅助奖励模型(本质上是正在训练的模型的几乎相同的副本),该模型学习根据人类偏好对训练模型的结果进行排名。
问题?
嗯,当今大多数奖励模型都是ORM,即结果监督奖励模型。通俗地说,为了评估模型预测的正确程度,他们会放眼全局,而忽略整个“思维过程”。
另一方面,PRM(过程监督奖励模型)评估模型响应中的每一步。因此,它们“迫使”模型密切关注并努力处理过程的每一步,这在解决如下数学方程等情况下至关重要:

然而,这是一个非常非常昂贵的过程,因为偏好数据需要大量的人工制作才能应用监控信号。因此,每个训练示例都有数十个或更多的奖励需要衡量。
因此,考虑到“gpt2-chatbot”在制定计划和执行复杂问题解决方面的熟练程度,“gpt2-chatbot”可能包含某种形式的奖励训练。
不可能不兴奋
考虑到 gpt2-chatbot 的疯狂性能,并牢记 OpenAI 最近的研究和泄密,我们现在可能对这个东西到底是什么有了一个很好的了解。
我们可以肯定的是,我们很快将面临一个完全不同的野兽,它将把人工智能的影响提升到一个新的水平。
- 我们是否终于达到了法学硕士超越人类水平的里程碑,就像我们对 AlphaGo 所做的那样?
- 长推理时代,也就是人工智能征服系统 2 思维的时代已经来临了吗?
可能不会。然而,我们很难不对接下来几个月我们将看到的疯狂发展感到高度乐观。
与此同时,我想我们将不得不等待才能得到这些答案。
