




由作者使用 DALL-E3 生成
数据云公司Snowflake发布了名为Arctic的新模型,因各种原因引起了企业界的关注。
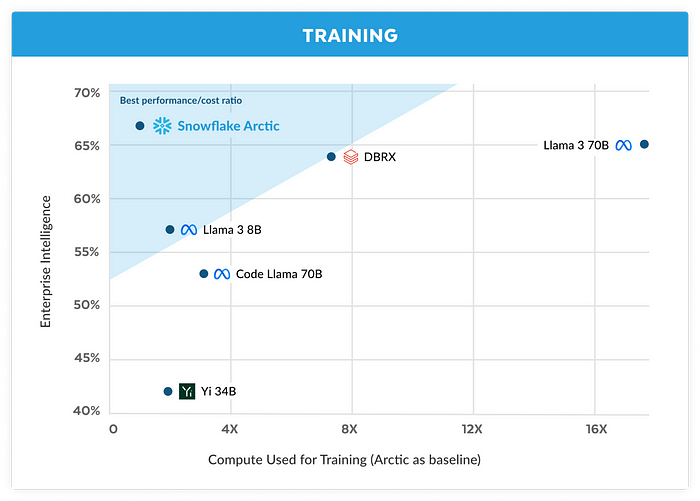
这是一款 480B 型号,在他们所谓的“企业智能”方面产生了令人印象深刻的性能(如果你感到畏缩也没关系,我也这么做了)。
抛开笑话不谈,事实是该模型在某些方面非常出色,并且训练预算不到200 万美元,这表明人工智能工程师在构建强大的法学硕士方面取得了多么出色的成绩。
此外,它非常让人想起我最近看到的最令人兴奋的架构之一,即超专业化的 MoE。
您可能已经厌倦了谈论这个或那个**如何**发生的人工智能时事通讯。这些时事通讯比比皆是,因为粗略地谈论已经发生的事件和事情很容易,但提供的价值有限,而且炒作被夸大了。
然而,谈论即将发生的事情的时事通讯却很少见。如果您想先于其他人对人工智能的未来进行易于理解的见解,那么TheTechOasis时事通讯可能非常适合您。
🏝️🏝️ 今天订阅如下:
科技绿洲
畏缩,但很棒
“企业智能”不过是针对编码、SQL 生成和指令跟踪的“企业相关”基准组合的模型结果的非加权平均值。
通俗地说,这个指标告诉我们该模型擅长这三件事,如果我们专注于超过 700 亿个参数的模型,这可能是最好的。
当然,基准是经过精心挑选的(一如既往),但它们仍然为模型描绘了一幅非常好的图画。
然而,拥有4800 亿个参数, 它仍然是巨大的。
仅此一头野兽就占用了至少 6 个最先进的 NVIDIA H100(每个 80GB HBM),而且这还不考虑KV 缓存、LLM 缓存以避免不必要的重新计算,这是考虑时最大的限制内存因素大序列。
当然,您也可以尝试对 HBM 执行部分加载,因为学术界已经在Apple等案例中这样做了,或者使用像 Predibase 这样的 LoRA 适配器(尽管后者并没有真正分解模型,它只是加载不同的精细模型) -将同一模型的版本调整到 GPU 中)。
然而,我们必须质疑这种变化对延迟的影响。
但这个模型最令人兴奋的地方在于:它是一个由 128 名专家和一名全球专家组成的深度混合专家,在推理时描绘了完全不同的现实。
深入专家
如果您需要更深入的解释,该架构与DeepSeek-MoE 的方法非常相似,您可以在此处查看。
在标准专家混合中,您将网络(令人惊讶的是)划分为专家。具体来说,对于任何给定的预测,模型需要执行(基本上是预测下一个单词),路由器会选择一组固定的专家来激活。
用更专业的术语来说,我们记得 LLM 只是 Transformer 块的串联,每个块都具有以下架构,其中Attention计算著名的注意力机制来处理模型接收的输入序列,RMS Norm稳定模型,MLP 层,称为前馈层(FFN)的层允许对语言中更复杂的统计分布进行建模,也可以帮助模型找到数据中更复杂的模式。
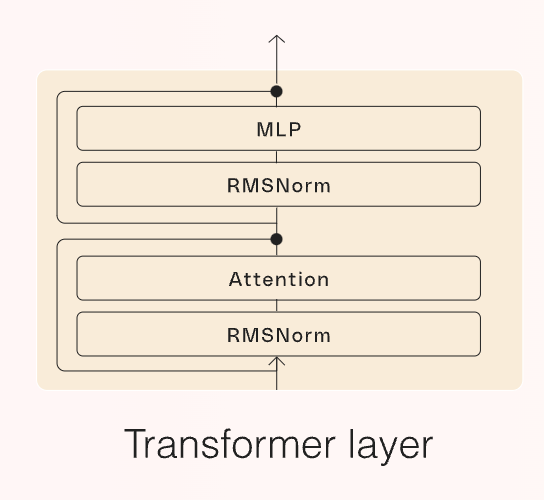
对于后者,由于它们具有大量的隐藏单元(神经元),它们代表了模型的大部分计算要求。
因此,在 Mixture-of-Experts 中,这些 FFN 层被分解为相同的部分,称为 Expert,前面有一个 softmax 门,如下所示。
无需深入了解我在上一个链接中提供的详细信息,该门将对每个输入的这些专家进行排名,选择最适合该工作的前 k 个。
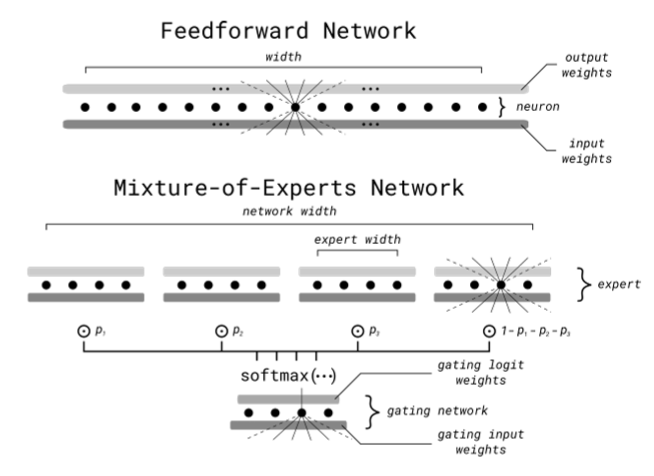
直观上,我们正在做的是迫使网络的不同部分专门研究特定主题。因此,我们对输入空间进行“区域化”,以从每个专家的不同神经元中寻找更高质量的数据压缩(更好的神经元),并且重要的是,随着每次预测运行的网络的一小部分,成本也更低。
然而,Arctic 就像DeepSeekMoE一样,采取了一种介于两者之间的方法。具体来说,它定义了两个专家类:
- 百亿参数专家每次运行
- 该模型包括 128 位专家,每个额外专家 3.66B,该模型为每个预测选择两名专家。
这给我们留下了一个与右下图极其相似的架构(左边的那个是标准 MoE),其中 1 号专家(全局专家,较大的专家)每次都会运行,而 2 号专家每次都会运行。另外还将选出128名专家参与预测。
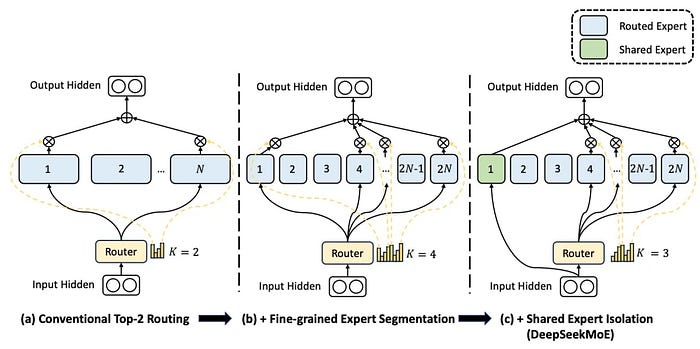
直观上,FFN 层仍然被分解,但路由器将始终从剩余的 128 个专家中选择“专家 1”和另外两名专家。
在计算方面,虽然模型的大小确实有 4800 亿个参数,但对于给定的预测,只有 17B或模型参数的 3.45%是活跃的。
因此,你拥有一个巨大模型的威力,而模型的成本仅为其实际尺寸的 4%。
请注意,成本和延迟的降低并不准确,因为 MoE 仅划分前馈层(尽管如此,它仍占 FLOP 的绝大多数),但注意力层保持不变。
企业法学硕士,另一种选择
尽管对于自称为“企业智能”之王的公司来说,这是令人尴尬的营销噱头,但事实是,北极似乎是一个非常有趣的选择。
此外,它再次证明了专家混合如何成为当今大多数模型的基本组成部分,以寻找大型模型和可持续推理之间的“最佳平衡点”。
款式不错,价格也实惠。
此外,值得一提的是,Snowflake或Cohere等公司明确押注,通过承认生成式人工智能在企业层面明显缺乏性能,他们的目标是结束它一直以来令人印象深刻的“人工智能之旅”。到目前为止,对于公司来说,虽然我们这个时代的 OpenAI 和 Anthropics 构建了下一代模型,但愿在这个过程中不会毁灭人类(我只是在开玩笑,别担心)。
