




由作者使用 ChatGPT-4o 生成
一年后,我们终于有了 OpenAI 的新模型,他们 Transformer 系列的最新版本,GPT-4o(“全模态”)。
它的文本、音频、图像和视频处理以及图像生成速度快得惊人。它还显示出明显的编码和多模式推理改进,同时支持 3D 渲染等新模式。
更重要的是,根据 lmsys.org 的聊天机器人竞技场,根据其代理模型(我们两周前讨论的著名的 gpt2-chatbot)获得的结果,它已经是最好的全能模型。
但这一次,发布背后的原因并不是山姆·奥尔特曼(Sam Altman)原话所说的“揭开无知的面纱” ,而是将最先进的人工智能免费提供给数十亿人。
以下是您需要了解的有关 ChatGPT-4o 的所有信息。
您可能已经厌倦了谈论这个或那个**如何**发生的人工智能时事通讯。这些时事通讯比比皆是,因为粗略地谈论已经发生的事件和事情很容易,但提供的价值有限,而且炒作被夸大了。
然而,谈论即将发生的事情的时事通讯却很少见。如果您想先于其他人对人工智能的未来进行易于理解的见解,那么TheTechOasis时事通讯可能非常适合您。
🏝️🏝️ 今天订阅如下:
科技绿洲
多模态的诅咒
尽管多模态大型语言模型 (MLLM ) 已经存在相当长一段时间了,但 GPT-4o 似乎是第一个真正跨四种不同模态的原生模型:音频、视频、图像和文本。
- 是的,像Gemini 1.5这样的模型对于后三个模型来说似乎是真正的多模态,但对于音频则不然。
- 事实上,GPT-4V允许音频处理/生成和图像生成,但通过与不同模型(即 Whisper、OpenAI TTO 和 Dall-e3)集成来实现这些功能。
与这些不同的是,ChatGPT-4o 是一种一体化模型,这意味着一个模型本身就可以与上述所有模式配合使用。
但这是什么意思呢?
多式联运输入、多式联运输出
尽管我将在本周四的免费新闻通讯中更详细地讨论这个问题(见上文),但我的想法是 ChatGPT-4o 不再是真正的“只是一个大型语言模型”。
大型语言模型 (LLM) 是序列到序列模型(输入是序列,输出也是序列),通常接收文本并输出其他文本。
当与图像编码器等组件结合使用时,它们还可以处理图像,这同样适用于其他模式。
但在许多情况下,这些成分是外源性的;它们实际上并不是模型的一部分。因此,法学硕士可以使用其输入来处理其他数据类型,但无法执行跨模式推理。
但是,这是什么意思?
正如米拉·穆拉蒂 (Mira Murati) 在官方演讲中强调的那样,演讲不仅仅包含言语。它还包括语气、情绪、停顿和各种其他线索,传达有关说话者正在交流的内容的附加信息。
比如,“我要杀了你!”如果说这句话的人表现出明确的意图或者他/她在句子中途大笑,那么可能会有非常不同的解释。
但到目前为止,ChatGPT 的先前版本实际接收到的只是语音转录,在此过程中丢失了所有其他线索。因此,该模型在解释语音时非常有限,前面的两个例子与其相同。
但现在,ChatGPT-4o 在同一模型中包含了处理和生成文本、图像、音频和视频(视频生成除外)的所有组件。换句话说,GPT-4o 是第一个结合了所有模式和原因的模型,就像人类一样。
了解了这一点,昨天推出了哪些令人兴奋的新功能?
全能野兽
尽管演示持续时间很短(30 分钟),但还是有很多值得一提的内容。
事实上,ChatGPT-4o 具有许多必要的特征,可以将 ChatGPT 从数百万人使用的产品转变为数十亿人使用的产品。
令人印象深刻的展示
首先,在我看来,最令人印象深刻的两件事之一可能是 ChatGPT 执行实时视频识别,谷歌告诉我们 Gemini 是这样,但实际上不是。
在另一个视频中,OpenAI 的 X 观众中有人建议进行实时翻译,而 ChatGPT-4o 可以完美地执行实时翻译,这要归功于另一个重大改进:人类水平的延迟。
如果您想知道为什么延迟下降了这么多,很可能是因为该模型不需要像之前那样将数据发送到其他模型,因为现在所有内容都由同一模型处理。
ChatGPT-4o 等语音助手对社会的另一个有趣的用例是教育,因为始终耐心的 AI 模型可以帮助学生学习复杂的任务:
该模型对复杂教育的帮助程度如何尚不确定。他们确实提到 ChatGPT-4o 具有“GPT-4 级别的智能”,因此将此演示更多地视为“对未来的看法”,而不是现在的实际情况。
内存是另一个非常有趣的功能,但在视频演示过程中却未被注意到。在下面的视频中,OpenAI 总裁 Greg Brockman 在他的视频帧中有一个“入侵者”,模型最初忽略了这个“入侵者”。
然而,当格雷格提示对其做出反应时,模型会回忆起之前发生的确切交互,这意味着两件事:
- 该模型似乎能够回忆起以前的事件
- 模型是否专注于某些任务而忽略其余任务似乎存在某种机制。这可能意味着 OpenAI 开发了一种具有分层重点的高性能视频编码机制。
换句话说,该模型有效地专注于在任何给定时间重要的事情,而忽略其余的事情,从而使整个过程更加高效,并且可能有助于解释尽管是高分辨率视频,但延迟却如此之低。
当然,X 为这一切而疯狂,并且出现了非常有趣的线索。给我印象最深的可能是OpenAI 的 Will Depue所做的,他展示了很多例子来证明 GPT-4o 的原生多模态。
该模型似乎在多代之间具有字符一致性,而没有任何明显使用控制网类型的图像调节:

在ControlNet中,您可以通过提供草图来影响生成扩散过程以生成新图像,然后模型将其用作生成图像的参考。在这里,只需提示模型让女孩和狗坚持新图像,它就会服从。
该模型甚至可以拍摄图像并生成替代的 3D 视图,然后将其组装成实际的 3D 渲染。

必须注意的是,GPT-4o 不是文本转 3D。然而,它可以生成不同的视图,然后可以用作 3D 渲染软件的输入,尽管许多人在 X 上声称如此。
除了演示之外,该模型似乎也是新的基准之王。
更智能,但不是 AGI
正如人们长期以来所怀疑的那样,并且lmsys.org 的 X 页面以及OpenAI 的研究人员也证实了这一点,“gpt2-chatbot”阵容的成员“im-also-a-good-gpt2-chatbot”是实际上一直都是 ChatGPT-4o。
在前者分享的图片中,gpt2-chatbots(又名 GPT-4o 聊天机器人)在整体 ELO(质量衡量标准)方面比GPT-4和Claude 3 Opus模型领先数英里。
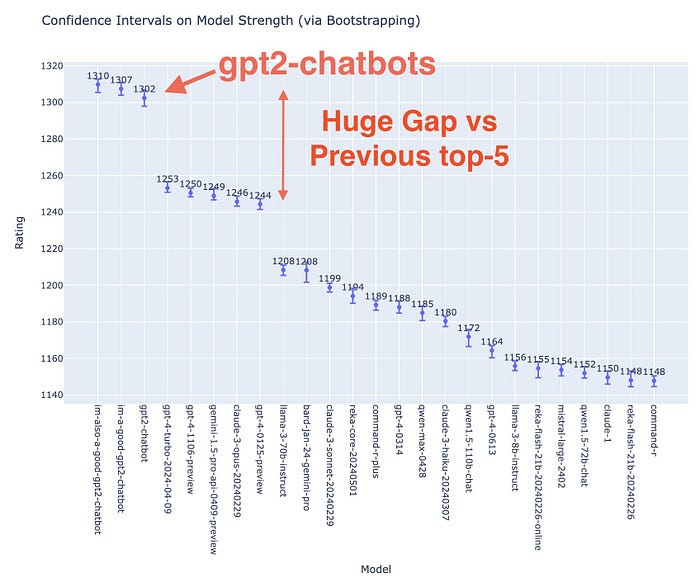
另一个明显的改进可以在编码中看到,改进增加了 100 个 ELO 点。作为参考,两个模型之间 100 分的差异意味着失败的模型只有 1/3 的时间被首选。
换句话说,ChatGPT-4o 与之前最先进的技术相比,在 66% 的情况下名列前茅。
具体来说,谈到编码,最引人注目的公告之一是 ChatGPT 桌面应用程序,它将提供对模型的全笔记本电脑屏幕访问,以支持您执行调试等任务,如本视频所示。
此外,该公告还对语言进行了重大改进。
服务了全球 97% 的人口
他们似乎极大地改进了模型的分词器,特别是在考虑非英语语言时(他们声称他们现在可以为世界上多达 97% 的人口提供服务,这是一个相当不错的声明)。
为了证明这一点,他们发布了一个表格,声称该模型对每种语言都有相当大的标记减少。
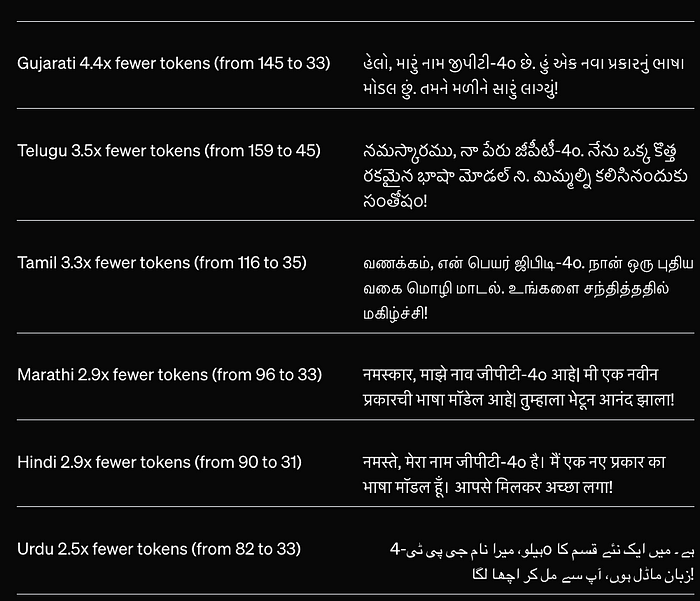
如果你想知道为什么压缩是相关的,他们基本上声称不仅可以更快、更高效地生成(必须生成的令牌越少越好),而且还展示了更大的“语言智能”。
通俗地说,一种语言拥有的标记越少,模型就越了解一种语言是如何生成的。
因此,随着模型变得更加智能,它将承认这一事实,而不是用三个不同的标记“i”、“n”和“g”生成该组合,因此生成过程会更慢且“更笨” ,它会知道它们很常见在一起,从而发现“ing”是英语生成的合适标记。
但 ChatGPT-4o 真的那么优越并且在智能方面实现了巨大飞跃吗?
嗯,不。
稳住,这不是 AGI
正如OpenAI 共享的图表所证明的那样,该模型无疑是目前最好的模型,但其相对于其他模型的智能改进却微乎其微。
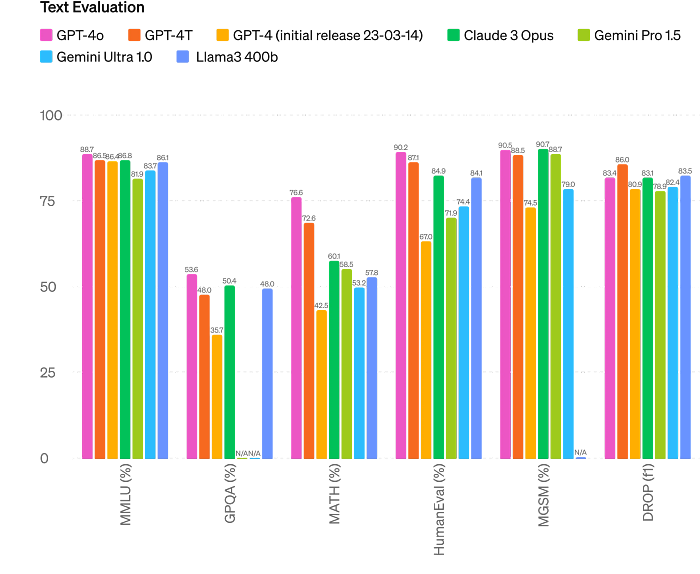
看到“智能”方面的改进,这个版本可能看起来平淡无奇。然而,我完全不同意,因为这个版本从来都不是关于下一个大前沿,而是其他事情。
然而,如果模型没有变得更智能,那还有什么意义呢?
OpenAI 的真实意图
在我看来,这个版本包含三个组成部分:
- 为下一个前沿领域的重大发布(即所谓的“GPT-5”)争取时间
- 闲聊今天举行的 Google I/O 大会
- 获胜苹果
我们一一来说吧。
下一个前沿已近,但尚未完全实现
OpenAI 的 CTO Mina Murati 公开谈到了这一点。 GPT-4o并不是智力的飞跃;事实上,他们明确表示它具有“GPT-4 级智能”。
此外,他们提到“很快”,我们将收到有关下一个前沿的新闻和更新,无论他们给它起什么名字。
正如我多次说过的,我的直觉告诉我,下一个前沿领域将把 MLLM 的世界与搜索算法合并起来,模型在实际回答之前探索不同的可能解决方案路径。
这是一个昂贵得多的范例,因此可以解释尽管模型总体上变得越来越小,但所有这些参与者似乎对购买越来越多的计算有多么浓厚的兴趣。
谷歌最可怕的噩梦
此时,如果你想预测 OpenAI 何时发布某些内容,只需看看 Google 会做什么。
例如,当 Google 为 Gemini 1.5 发布了相当引人注目的百万上下文窗口时,MLLM 在任何给定时间可以处理的数据量发生了巨大飞跃,OpenAI 完全改变了叙述方式并发布了他们的视频生成模型 Sora。
现在,在备受期待的 Google I/O 大会今天召开之前,OpenAI 在前一天也举行了自己的大会,这为今天的分析师对前者设定了极高的期望。
简而言之,这不是谷歌展示其新的人工智能功能;而是展示其新的人工智能功能。现在的情况是“让我们看看谷歌如何根据 OpenAI 的公告做出回应”。
我们可以同意也可以不同意萨姆·奥尔特曼疯狂的侵略性竞争方式。但是男孩,它有效。在这个世界上,除了这个人之外,我不愿意与之战斗的人很少。
最后,考虑到目前正在拍卖的 Google 和 OpenAI 之间为争夺 Siri 桂冠而传闻甚嚣尘上的“战斗”,我们需要谈谈苹果。
一直以来的目标?
如果我们考虑与苹果合作的潜在回报,获得 Siri 的合同可能一直是 OpenAI 的目标。
凭借在延迟、轻浮的语音行为、跨多种数据类型的强大功能以及重要的是出色的屏幕视觉功能等方面的强大展示,OpenAI 让 Apple 成为他们的犯罪伙伴以增强原始能力已经不是什么秘密了。西里。
事实上,除非苹果推出令人惊叹的设备模型,否则用户不会在意,并会立即将其与最先进的技术进行比较。
因此,尽管这对于苹果公司来说显然不是一个很好的公关前景,因为这家公司现金如此充裕,以至于进行了资本主义历史上最大规模的股票回购(1310亿美元),但仍然无法修复 Siri,但苹果公司几乎没有什么可以解决的问题。这一点不允许有任何错误。
因此,当他们清理内部“人工智能混乱”并开始提供优秀的人工智能产品时,押注 GPT-4o(或谷歌今天展示的内容)的诱惑将会很大。
如果是这样的话,我们就必须大胆猜测,以了解这种伙伴关系将如何实现。
苹果以极其热衷于保护用户隐私而闻名,这似乎与一家公司为 Siri 提供基于云的 LLM 解决方案不兼容,该公司在训练模型时明确违反了版权和安全规则。
但是,当道德妨碍金钱时,我们知道公司会选择什么,无论决策的道德性如何。
也许 OpenAI 能够提供设备上的 ChatGPT,这是一个非常小的模型,具有与 ChatGPT-4o 类似的功能,可以完成这项工作,但这只是我的猜测。
从数百万到数十亿
总而言之,OpenAI 从未让人失望。但这一次,他们的意图可能不像过去那么明显。
GenAI 产品以不兑现承诺而闻名,即使对于 ChatGPT 这样的案例也是如此。延迟和糟糕的跨模式推理等因素会阻止这种情况发生。
现在,OpenAI 认为它最终拥有的产品能够满足人们对“互联网以来最大发现”的高度期望。
虽然现在判断情况是否属实还为时过早,但这确实给了他们足够的弹药来吓唬谷歌,并为他们有史以来最大的版本——人工智能的下一个前沿——赢得足够的时间。
尽管如此,GPT-4o 仍然有局限性,而且它显然并不比 GPT-4 更接近 AGI。
但它确实让生成式人工智能更贴近社会,让强大的人工智能广泛可用(该产品将是免费的),如果他们拥有 Siri,甚至可能惠及数十亿人,而这正是人工智能开始兑现其承诺所需要的。
