




一、简介
像往常一样,这个周末我辅导女儿做中文作业。我发现了一首诗,完美地反映了不断发展的生成人工智能代理。这首诗的标题是“人有两件宝”或“我们每个人都有两件宝”,优雅地反映了大语言模型Agent概念的核心精髓。这首诗谈到了每个人都拥有的两项财富:我们的双手和大脑。
我们的手代表着行动的能力——操纵工具、制作物体、移动物体。我们的大脑象征着思考、推理、计划、反思和记忆的能力。
行动和反思的二元性是生成人工智能代理技术的基础,就像我女儿的中国诗中描述的使用手和大脑一样:
“如果单靠双手来完成一项任务,
不经过深思熟虑,就要求太多了。
如果我们只用大脑的话,
没有我们的双手,线索有什么用呢?
但同时使用它们,强大,
和谐相处,他们不会出错。
双手和大脑并肩,
没有什么事情是我们做不到的,只要我们有骄傲的心!”
照片由Júnior Ferreira在Unsplash上拍摄
在本文中,我们将讨论代理技术的基本概念,探讨它们如何规划、利用工具、合并内存以及在多代理系统中进行协作以增强其功能。通过了解这些元素,我们可以了解基于代理的系统如何在人工智能的前沿发展。
2. Agent框架概述
代理框架由规划、工具和内存组成。每个人对于代理的运作和成功都起着至关重要的作用。
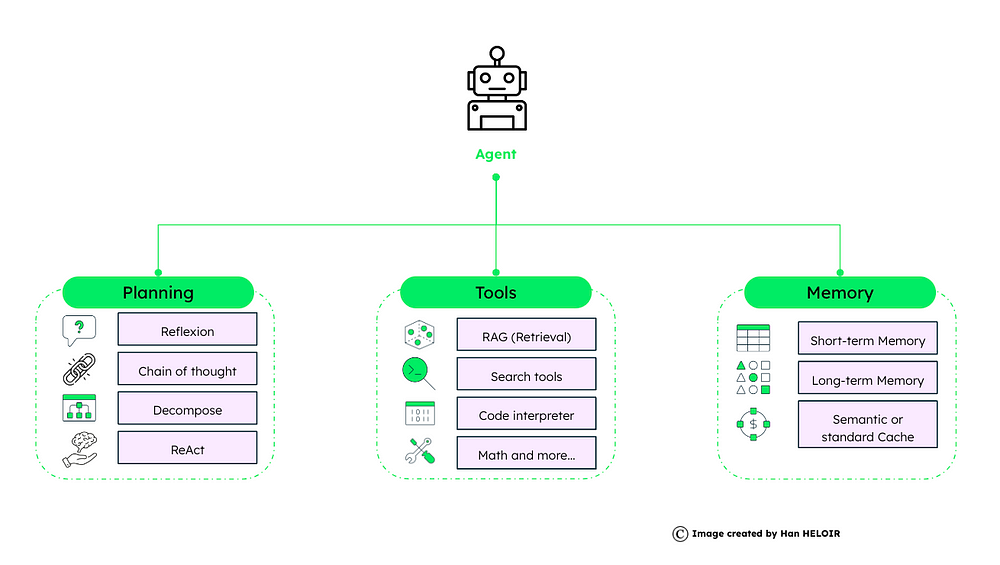
代理框架概述
2.1 规划
规划是智能体的战略要素,通过规划智能体确定实现目标的步骤。有几种技术:
反思:代理思考他们从任务中获得的反馈,然后写下他们的情节记忆,以帮助他们在下一步中做出更好的决策。这是智能体内部的一种自我改进机制,使其能够从过去的行为中学习,反思结果,并在未来的任务中做出更好的决策。
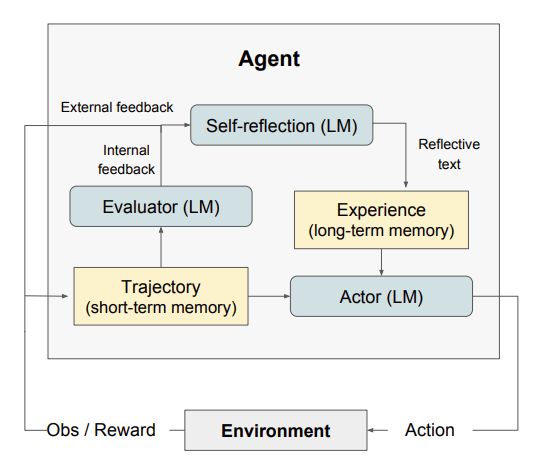
摘自论文“反射:具有言语强化学习的语言代理
” https://arxiv.org/pdf/2303.11366
思维链:我们可以利用提示技术,要求大语言模型建立一个类似于人类推理的一步步思维,从而得出结论或答案。
最近的学术著作如“思想之树”和“思想算法”提出了通过采用基于树或基于图的数据结构进行上下文管理的提示策略,从而减少了所需提示的数量。
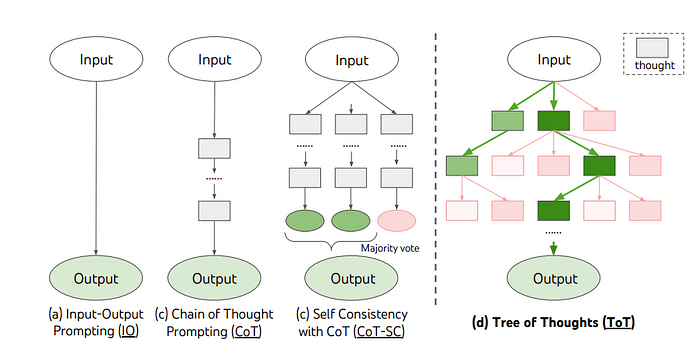
来自论文:“思想之树:使用大型语言模型深思熟虑地解决问题” https://arxiv.org/pdf/2305.10601
分解:代理可以将复杂的问题分解为更小、更易于管理的部分。从那里,我们可以利用不同的工具来处理模块化问题。
ReAct:这个过程结合了反射(推理)和行动,使代理能够迭代地思考、行动和观察,以动态地解决复杂的任务。
这个概念在论文“ ReAct:在语言模型中协同推理和行动”中得到了阐述,该论文已经被 LangChain 和 LlamaIndex 在他们的代理框架中实现。
2.2 工具
一旦我们制定了解决问题的计划,工具就是使代理能够执行这些计划的功能方面。
检索/RAG: RAG 代表检索增强生成,这是一种通过集成外部数据、向量存储中的外部信息或任何大型数据集来增强代理响应的工具。
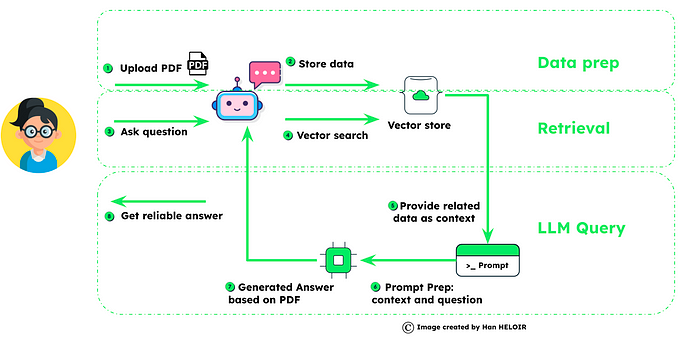
什么是RAG?
搜索工具:代理可以使用各种实用程序来导航和检索信息,从而帮助他们进行决策过程。如维基百科、塔维利
代码解释器:帮助代理更好地理解和执行代码的外部工具,这对于开发生成式人工智能应用程序非常重要。
数学工具:专用于数学计算的工具。
自定义工具:我们可以在自定义工具中利用任何外部函数或外部 API 端点,这为代理提供了巨大的可能性。
作者自定义工具的示例
2.3 内存
智能体的记忆有两类:短期记忆和长期记忆。
短期记忆:上下文记忆允许代理利用大语言模型的短期记忆从头开始操作原始问题。此功能允许代理暂时保存信息并在任务执行需要时对其进行处理。
长期记忆:对话结束后保留和回忆信息的能力。我们经常利用外部数据库来扩展这些知识,这对于进一步的知识学习可能是宝贵的。
语义或标准缓存:作为长期记忆的扩展,可以将指令对和LLM答案存储在数据库、向量存储或具有向量功能的数据库中。在向 LLM 发送下一个查询之前,代理可以检查缓存以加快响应时间并降低调用基于 API 的 LLM 的成本。
3. 使用加速器的代理实现
随着人们意识到代理是生成式人工智能的未来,许多技术堆栈和 Clouder 提出了构建人工智能代理的方法。在本节中,我们将介绍一些主要的技术堆栈及其建议。
3.1 浪链代理
使用 AgentExecutor 进行规划和执行:
在执行层面,LangChain采用了AgentExecutor,它代表了代理的推理大脑——语言模型和它可以调用的工具——到一个连贯的运行时环境中。
在这里,代理决定操作,然后由 AgentExecutor 执行。这种决策制定和行动执行的分离封装了软件工程中的最佳实践设计模式,从而增强了可维护性和可扩展性。
使用 LangChain 定义代理工具:
代理工具的创建是LangChain实用程序的核心部分。例如,它集成了 Wikipedia 搜索、YouTube、Yahoo 搜索、Google Scholar 等 60 多个工具,您可以直接在 AI 应用程序中利用这些工具。
除了与 LangChain 集成的工具之外,您还可以创建自己的工具,例如从操作数据库创建检索工具来获取产品目录。
合并内存:
LangChain还解决了代理记忆的挑战。尽管它只是测试版本,但通过合并聊天历史的机制,代理能够进行有状态的交互,记住并建立在以前的交换基础上。此功能对于在对话或任务序列中提供连续性和上下文至关重要,从而实现与用户更加人性化的交互。
代理类型:
在LangChain中,代理类型根据其预期的模型类型、支持聊天历史的能力、处理多输入工具以及进行并行函数调用的能力进行分类。以下是一些示例:ReAct 代理、带有搜索代理的 Self Ask 和工具调用代理。
代理类型的选择应与模型的功能和预期任务的复杂性相一致。
使用 Langchain 创建 Agent 的实际示例:
此代码设置一个自定义代理,能够执行任务并在多个交互中维护对话状态。它将工具绑定、提示模板、内存管理和执行器逻辑结合到一个利用 OpenAI API 的对话式 AI 模型的全面设置中。该示例可以作为开发针对特定用例定制的更复杂代理的基础框架。 ( langchain提供的最新代码请参考此链接。)
from langchain_openai import ChatOpenAI
from langchain.agents import tool
# 加载语言模型
llm = ChatOpenAI (model= "gpt-3.5-turbo" , temperature= 0 )
# 定义一个简单的工具
@tool
def get_word_length ( word : str) -> int :
"" "返回单词的长度。" ""
return len (word)
# 工具调用示例
get_word_length. invoke ( "abc" )
tools = [get_word_length]
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 创建提示模板
Prompt = ChatPromptTemplate. from_messages (
[
( "system" , "你是个很厉害的助手,但是不知道时事" ),
( "user" , "{input}" ),
MessagesPlaceholder (variable_name= "agent_scratchpad" ),
]
)
# 绑定LLM 的工具
llm_with_tools = llm. bind_tools (tools)
from langchain.agents.format_scratchpad.openai_tools import format_to_openai_tool_messages
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParser
# 创建代理
agent = (
{
"input" : lambda x: x[ "input" ],
"agent_scratchpad" : lambda x: format_to_openai_tool_messages (
x[ "intermediate_steps" ]
),
}
|提示
| llm_with_tools
| OpenAIToolsAgentOutputParser ()
)
from langchain.agents import AgentExecutor
# 初始化代理执行器
agent_executor = AgentExecutor (agent=agent, tools=tools, verbose=True)
# 使用代理的示例
print ( list (agent_executor.stream ({ " input " : "单词 educa 有多少个字母" })))
# 向代理添加内存
MEMORY_KEY = "chat_history"
Prompt = ChatPromptTemplate.from_messages (
[
( “系统”,“你是个很厉害的助手,但是不擅长计算单词的长度。” ),
MessagesPlaceholder (variable_name=MEMORY_KEY),
( "user" , "{input}" ),
MessagesPlaceholder (variable_name= "agent_scratchpad" ),
]
)
from langchain_core.messages import AIMessage, HumanMessage
# 设置内存跟踪
chat_history = []
#使用内存更新了代理 agent
= (
{
"input" : lambda x: x[ "input" ],
"agent_scratchpad" : lambda x: format_to_openai_tool_messages (
x[ "intermediate_steps" ]
),
"chat_history" : lambda x: x[ "chat_history " ],
}
| Prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser ()
)
agent_executor = AgentExecutor (agent=agent, tools=tools, verbose=True)
# 使用内存运行代理
input1 = "educa 这个词有多少个字母?"
结果 = agent_executor.调用({ “输入”:input1,“聊天历史记录”:聊天历史记录})
聊天历史记录。扩展(
[
HumanMessage(内容=输入1),
AIMessage(内容=结果[ “输出” ]),
]
)
agent_executor。invoke ({ "input" : "这是一个真实的单词吗?" , "chat_history" : chat_history})
3.2 具有 LlamaIndex 的代理
由 LlamaIndex 提供支持并由 LLM(大型语言模型)增强的数据代理与我们在第 2 节中解释的非常相似。有三个主要组件:
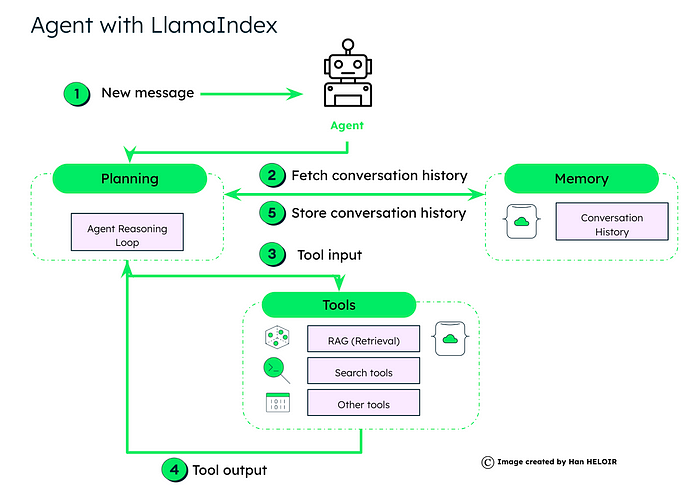
LlamaIndex 代理框架概述
规划:具有“代理推理循环”逻辑。当代理收到新的用户消息时,代理使用“释放循环”来决定是否需要获取历史内存,决定使用哪些工具、以什么顺序以及调用每个工具的参数。
推理循环是智能体运行的核心,支持多种智能体类型,包括:
- 函数调用代理:与函数调用 LLM 完美搭配。
- ReAct Agent:适用于聊天/文本完成端点。
- 高级代理:例如 LLMCompiler、Chain-of-Abstraction、语言代理树搜索等。
工具:代理提供了一组工具,可以决定使用什么工具。根据当前的查询和对话历史记录,代理确定参与的必要工具。这些可能包括用于信息检索的 RAG、特定搜索工具或其他定制功能。
所选工具处理输入并生成输出,其中可能包括数据检索结果、计算值或要采取的操作。
记忆:代理从记忆中检索对话历史记录,确保其响应的连续性和上下文。处理后,代理会更新内存中的对话历史记录以供将来参考,从而保留交互流程。
LlamaIndex 中的数据代理具有以下能力:
- 通过高级接口端到端执行用户查询。
- 提供用于逐步执行的低级 API,从而对任务进展和分析进行精细控制。
数据代理可以按照提供的使用模式中所示进行实例化和操作,其中它从一组工具进行初始化。例如,可以使用各种工具创建 ReAct 代理来支持聊天和查询功能。此外,这些代理继承自 ChatEngine 和 QueryEngine,它们可以提供。
在 LlamaIndex 中实现数据代理的示例
在本手册中,以下是使用具有函数调用功能的 OpenAI API 在 Python 中构建自定义 OpenAI 代理的示例。此示例包括会话上下文中的工具创建、代理设置和代理交互。
# 导入必要的库和包
import json
from waiting import Sequence , List
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool, FunctionTool
from openai.types.chat import ChatCompletionMessageToolCall
import Nest_asyncio
# 应用必要的异步调整
nest_asyncio.apply()
# 为代理定义计算工具
def multip ( a: int , b: int ) -> int :
"""将两个整数相乘并返回结果"""
return a * b
def add ( a: int , b: int ) -> int :
"""将两个整数相加并返回结果"""
return a + b
# 从定义的函数创建 FunctionTool 实例
multip_tool = FunctionTool.from_defaults(fn=multiply)
add_tool = FunctionTool.from_defaults(fn=add)
# 定义自定义 OpenAI 代理类
class YourOpenAIAgent :
def __init__ ( self, tools: Sequence [BaseTool] = [], llm: OpenAI = OpenAI( Temperature= 0 , model= "gpt-3.5- Turbo-0613" ), chat_history:列表[ChatMessage] = [] ) -> None :
self._llm = llm
self._tools = {tool.metadata.name:工具中工具的工具} self._chat_history = chat_history def reset ( self ) -> None : """重置对话历史记录""" self._chat_history = [] def chat ( self, message: str ) -> str : """通过代理处理消息,管理工具调用和响应""" self._chat_history.append(ChatMessage(role= "user" , content=message)) 工具 = [tool.metadata.to_openai_tool() for _, tool in self._tools.items()] ai_message = self._llm 。聊天(self._chat_history,工具=工具).message
self._chat_history.append(ai_message)
# 处理并行函数调用
tool_calls = ai_message.additional_kwargs.get( "tool_calls" , [])
for tool_call in tool_calls:
function_message = self._call_function(tool_call)
self._chat_history.append(function_message)
ai_message = self._llm.chat(self._chat_history).message
self._chat_history.append(ai_message)
return ai_message.content
def _call_function ( self, tool_call: ChatCompletionMessageToolCall ) -> ChatMessage:
"""基于工具调用调用函数" ""
tool = self._tools[tool_call.function.name]
输出 = tool(**json.loads(tool_call.function.arguments))
return ChatMessage(name=tool_call.function.name, content= str (output), role = "tool" , extra_kwargs={ "tool_call_id" : tool_call. id , "name" : tool_call.function.name})
# 创建并测试代理
agent = YourOpenAIAgent(tools=[multiply_tool, add_tool])
print (agent.chat ( "Hi" )) # 预期响应:模型的问候或提示
print (agent.chat( "What is 2123 * 215123" )) # 预期响应:乘法结果
3.3 具有 AWS 基础的代理
以下是 AWS Bedrock 中代理的流程。该过程分为两个主要部分:初始用户输入处理和核心操作循环:
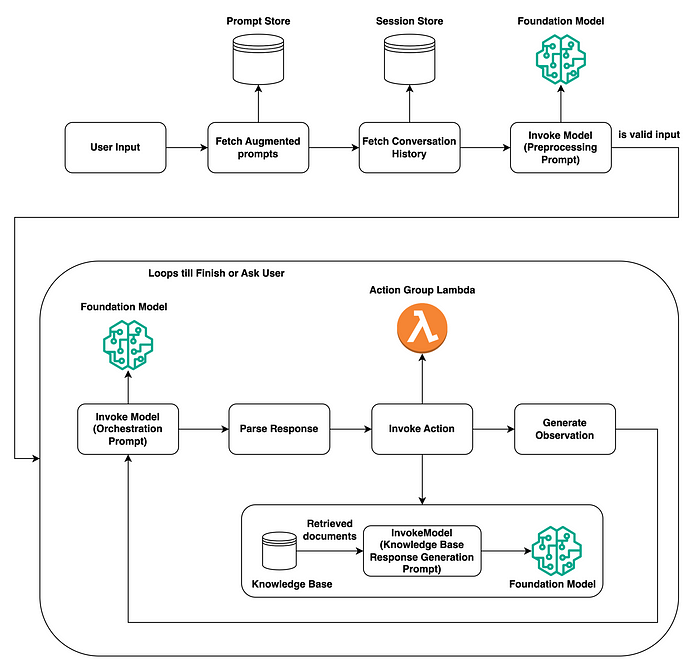
图表来自 AWS 博客“如何构建代理”
用户输入处理:
- 在接收用户输入时,代理会检查提示存储以获取增强的提示,然后我们检查会话存储以获取对话历史记录。
- 调用基础模型(可以是大型语言模型)来预处理提示以确定其有效性并理解用户的意图。
核心行动循环:
- 然后再次调用基础模型,这次是为了编排提示/制定行动计划,同时考虑到之前获取的提示和历史记录。
- 然后解析响应,并基于此,代理决定是否调用操作或从知识库获取其他文档以通知其响应。
- 如果调用某个操作,则可以触发操作组 Lambda 函数来执行该操作并生成观察,这可能会导致文档的 RAG/检索。
- 此循环继续 – 调用模型、解析响应、调用操作并生成观察结果 – 直到代理完成任务或要求用户提供更多信息。
AWS 代理用户界面
如何在AWS中创建代理?
AWS Bedrock 中的代理由几个关键组件组成:
- 基础模型 (FM):选定的 AI 模型,用于解释用户输入并编排响应流。
- 说明和高级提示:编写了详细的指南来指导代理在每个步骤的操作和逻辑。
- 操作组:可选组件,包括 OpenAPI 架构和 AWS Lambda 函数,定义代理可以调用以完成任务的 API 操作。
- 知识库:多个矢量数据库可选地与代理相关联,提供上下文以增强代理的响应。包括 OpenSearch、Redis、Pinecone 和 Amazon Aurora。
您可以参考以下屏幕截图来大致了解在 AWS 中创建这些组件。
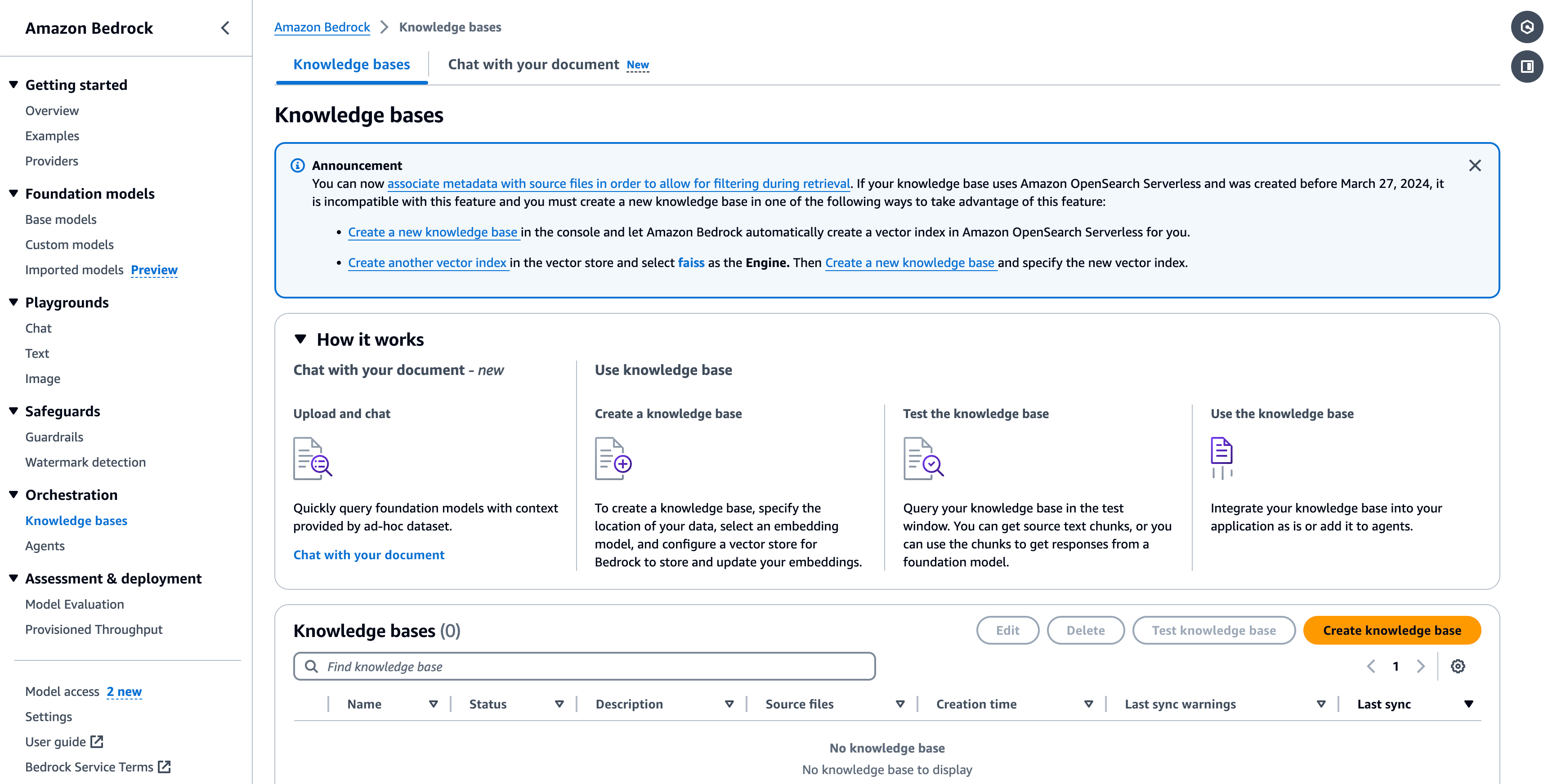
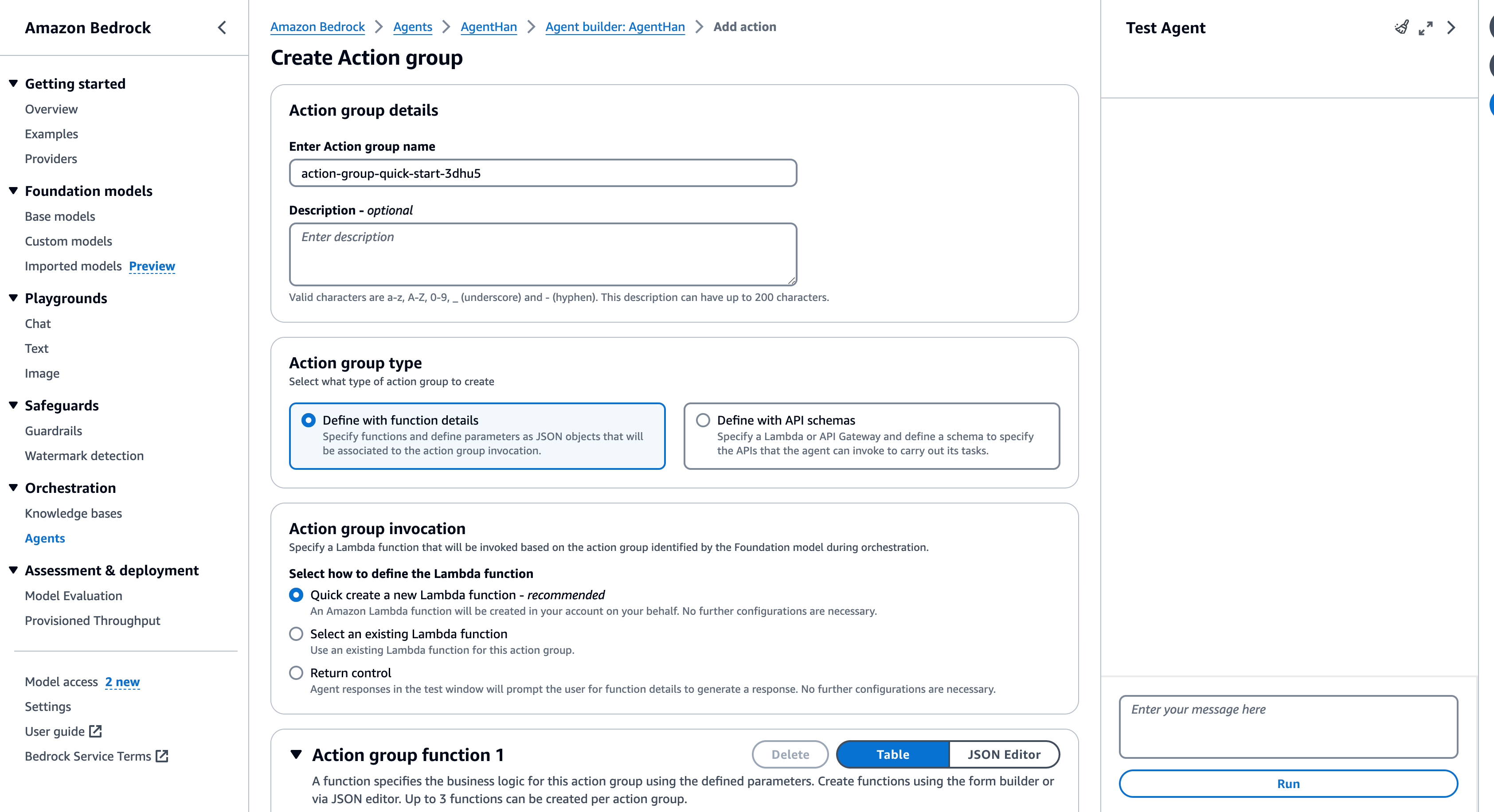
用于创建知识库和操作组的 AWS UI
3.4 使用 Gemini 的代理生成器
自 2024 年 4 月起,Google 发布了 Vertex AI 代理 Builder。 Agent builder 是一款旨在利用 GCP 加速 AI 代理创建的工具。
在 UI 上,我们可以轻松定义代理以及我们希望代理实现的目标、提供说明并共享对话示例。
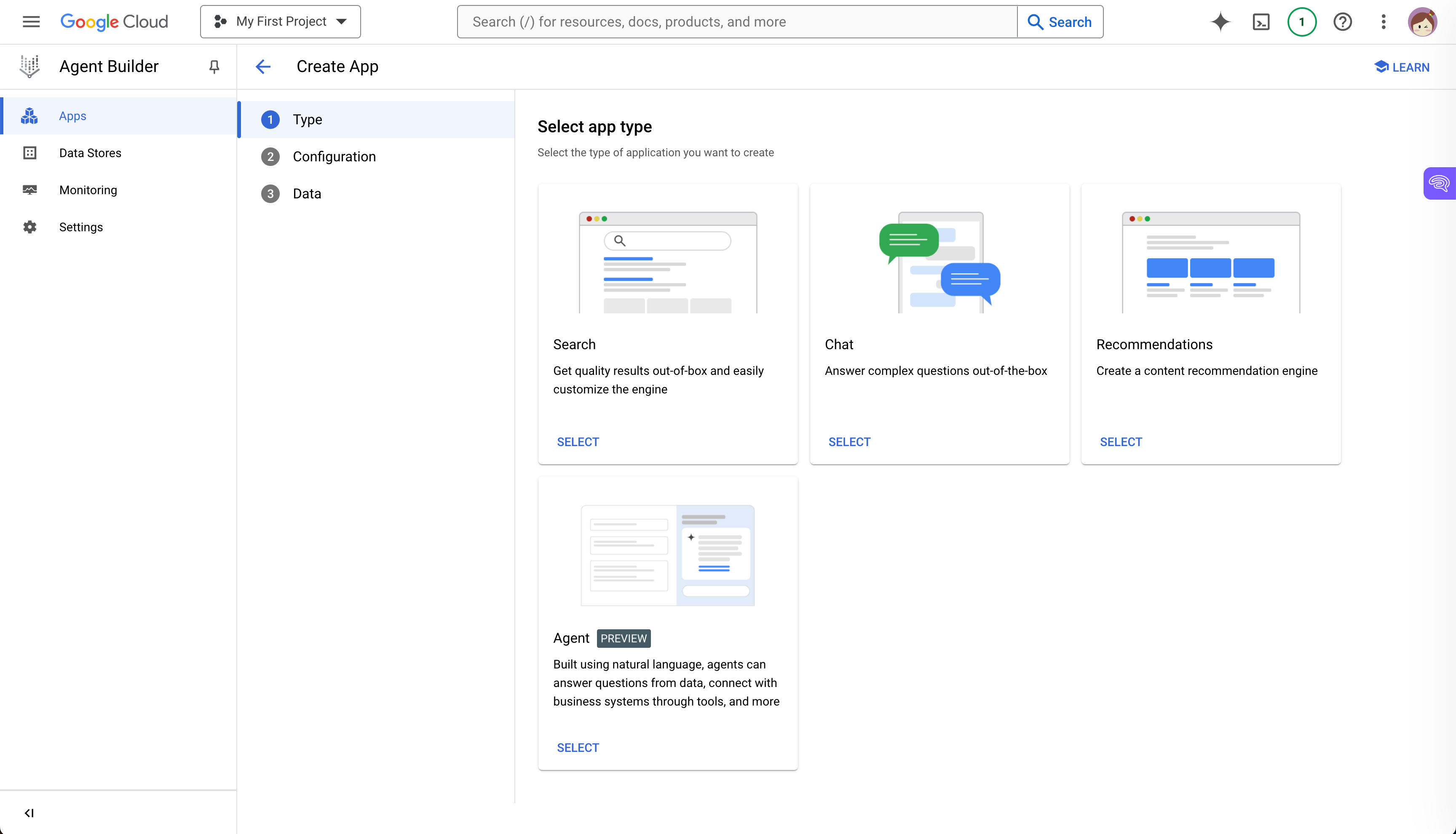
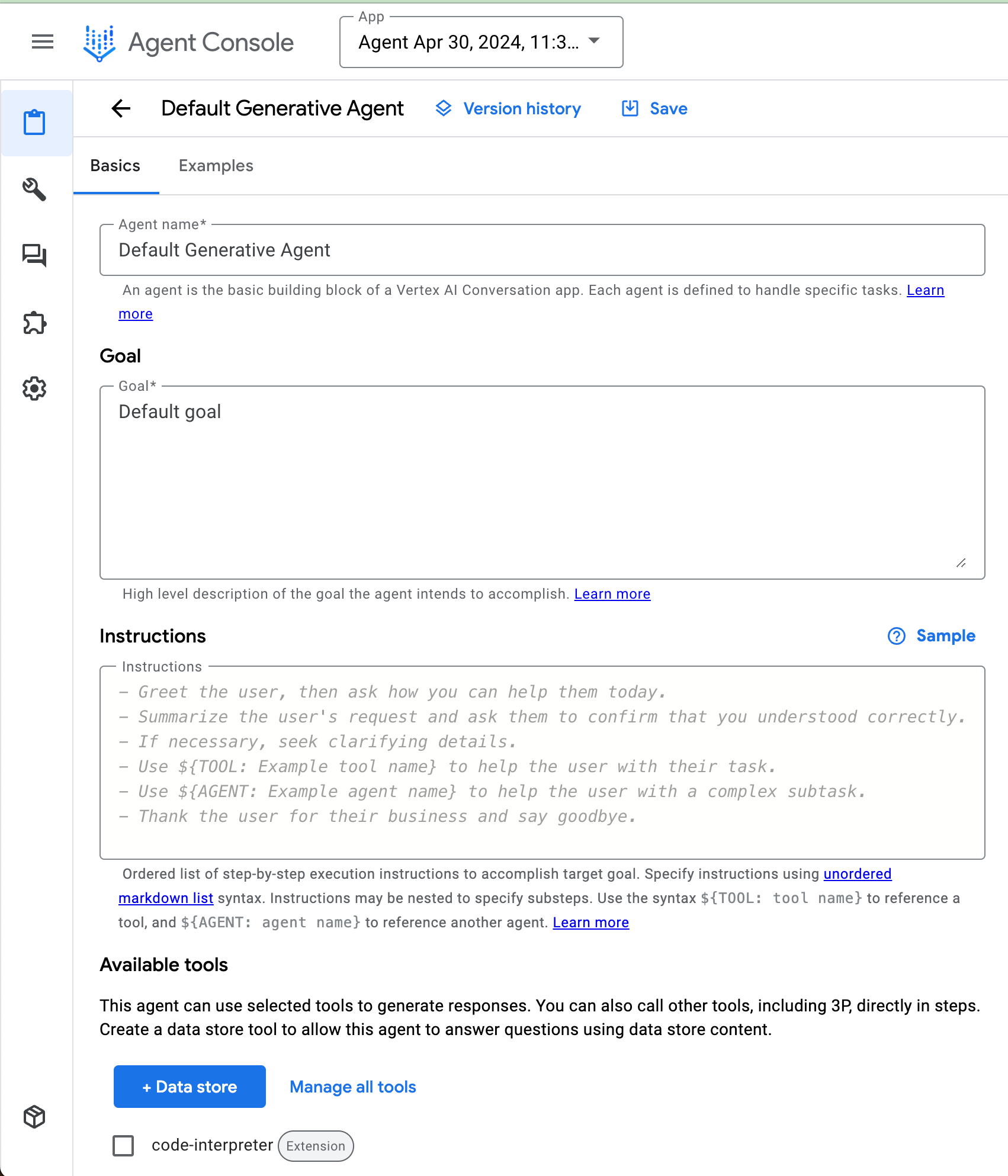
通过Agent Builder,我们还可以使用GCP中存储的企业数据来基础模型。我们可以调用函数并连接到应用程序来执行用户任务。

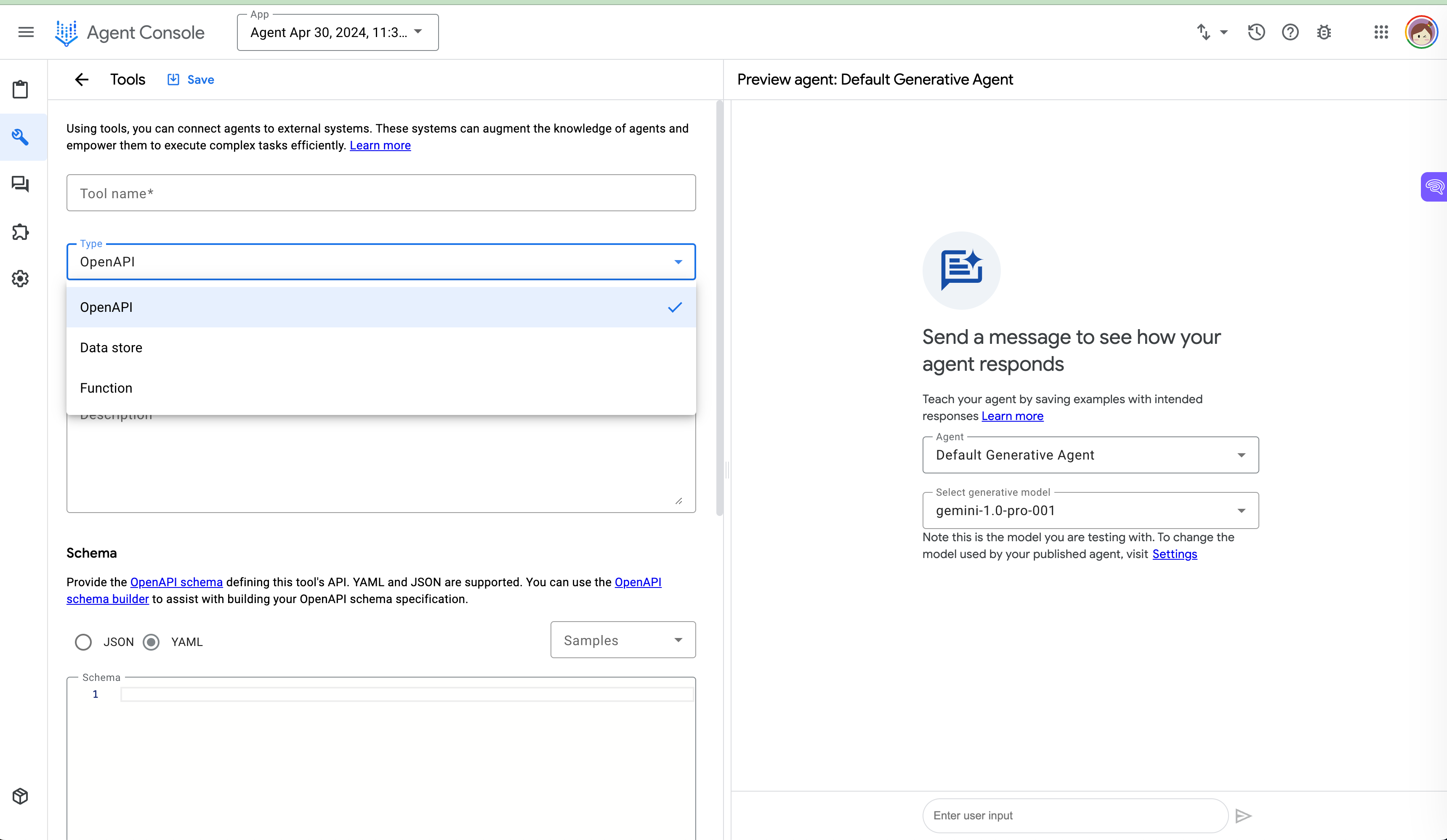
作者在 Agent Builder 中的数据存储和工具
4. 多Agent框架
人工智能代理领域仍处于早期阶段。每个框架或开发堆栈都有其构建独立代理的方法。然而,人们很快就会发现,当代理协作工作时,它们会增强其功能并扩大其应用范围。这种合作带来了两个主要挑战:
- 编排涉及多个代理的工作流程
- 由于每个代理使用的接口通常不同,因此在代理之间建立通信很困难
4.1 微软AutoGen
为了应对代理编排的挑战,微软于 2023 年 10 月推出了AutoGen 框架。AutoGen旨在简化多代理应用程序的开发,特别是在编排 LLM 代理方面。
AutoGen 提供了一个多代理对话框架作为高级抽象。它是一个开源库,用于支持具有多代理协作的下一代 LLM 应用程序。
通过使用 AutoGen,我们可以创建配备不同大语言模型的代理。我们可以有不同类型的代理:一种用于代码生成和执行的代理,一种用于人类反馈和参与的代理。
考虑一个实际的例子:一个热衷于学习中文的用户。通过 Autogen,我们部署了三个代理——一个与用户互动,另一个规划课程,第三个提出课程内容。用户与用户代理交互,让他们选择验证课程计划。然后,教学代理从 VectorDB 中获取学习材料,根据用户偏好构建日常课程。
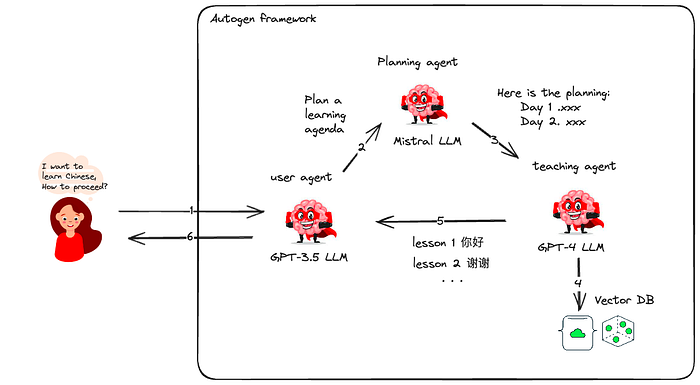
如果您想了解更多关于 AutoGen 的信息,可以参考我之前的文章:AutoGen 深入而简单 且无代码的 GenAI 代理工作流程编排:AutoGen Studio 与本地 Mistral AI 模型。
4.2 船员人工智能
CrewAI 系统旨在模仿人类团队合作的动态和协作本质,其中每个代理的独特技能和属性都有助于实现共同目标。它为人工智能驱动的任务执行引入了效率和结构。
CrewAI框架建立如下:
- 代理:使用特定属性和功能进行初始化。
- 任务:目标和预期结果的详细描述。
- 工具:代理的工具箱,使他们能够有效地执行各种操作。
- 流程:战略工作流程规定了工作人员如何处理和完成任务。
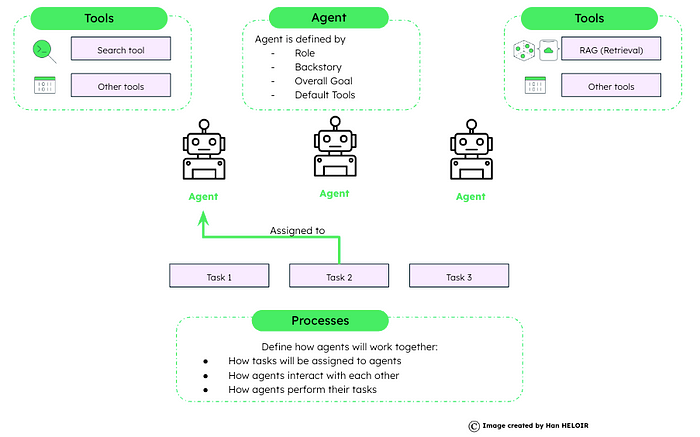
船员人工智能工作流程
一个用crewAI实现的例子
首先,我们安装必要的crewAI软件包和工具。
# 所需安装 !pip installrewai !pip install 'crewai[tools]'
在这个例子中,有4个步骤:
- 代理定义:配置两个代理,一个研究员和一个作家,每个代理都配备特定的角色、详细模式、内存和背景故事来指导他们的交互。
- 任务定义:概述代理的具体任务,详细说明目标和预期输出,以及与任务相关的配置,例如异步执行和输出文件规范。
- 团队组建:将代理组合成具有定义流程和增强配置(例如内存使用和任务共享)的团队。
- 执行:启动流程,将输入变量输入系统以实现个性化方法,并打印团队协作的结果。
# 导入必要的库
import os
from craftai import Agent, Task, Crew, Process
from craftai_tools import SerperDevTool
# 设置环境变量
os.environ[ "SERPER_API_KEY" ] = "Your Key" # serper.dev API key
os.environ[ "OPENAI_API_KEY " ] = "Your Key"
# 定义具有不同角色和功能的代理
search_tool = SerperDevTool()
Researcher = Agent(
role= '高级研究员' ,
goal= '发现{topic}中的突破性技术' ,
verbose= True ,
memory= True ,
backstory=( "在好奇心的驱使下,您处于创新的最前沿,渴望探索和分享可以改变世界的知识。" ),
tools=[search_tool],
allowed_delegation= True
)
writer = Agent(
role= ' Writer' ,
goal= '讲述有关 {topic} 的引人入胜的科技故事' ,
verbose= True ,
memory= True ,
backstory=( “凭借简化复杂主题的天赋,您可以编写引人入胜的叙述,吸引人并具有教育意义,带来新的发现" ),
tools=[search_tool],
allowed_delegation= False
)
# 定义具有特定目标的任务
Research_task = Task(
description=( "识别 {topic} 中的下一个大趋势。专注于识别利弊和整体叙述。你的最终报告应清楚地阐明要点、市场机会和潜在风险。" ),
Expected_output= '关于最新人工智能趋势的综合性 3 段长报告。' ,
tools=[search_tool],
agent=researcher,
)
write_task = Task(
description=( "撰写一篇有关 {topic} 的有洞察力的文章。关注最新趋势及其对行业的影响。这篇文章应该易于理解、引人入胜,并且积极。” ),
Expected_output= '关于 {topic} 进展的 4 段文章,格式为 markdown。' ,
tools=[search_tool],
agent=writer,
async_execution= False ,
输出文件 = 'new-blog-post.md'
)
# 组成一个配置有代理和任务的组
rewrew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential, #默认顺序执行任务
memory= True ,
cache= True ,
max_rpm= 100 ,
share_crew= True
)
# 启动任务执行过程
result =船员.kickoff(inputs={ 'topic' : 'AI in Healthcare' })
print (result)
4.3 代理协议
代理协议被设计为用于与不同代理进行通信的单一通用接口,旨在解决我们提到的多代理系统的第二个挑战。
任何代理开发人员都可以实现此协议。代理协议是一个 API 规范 – 端点列表,代理应使用预定义的响应模型公开这些端点。该协议与技术堆栈无关。任何代理都可以采用此协议,无论他们使用什么框架,如第 3 节(或不)中所述。
该协议如何运作?
目前,该协议被定义为 REST API(通过 OpenAPI 规范),具有与代理交互的两个基本途径:
- POST /ap/v1/agent/tasks用于为代理创建新任务(例如为代理提供您想要完成的目标)
- POST /ap/v1/agent/tasks/{task_id}/steps用于执行定义任务的一个步骤
它还具有一些用于列出任务、步骤和下载/上传工件的附加路径。
如果您想了解更多信息,请参阅代理协议GitHub 。
5. 结论
生成式人工智能的未来令人兴奋。规划、使用不同工具和保留记忆的能力将使代理与法学硕士一起表现得更好。来自LangChain、LlamaIndex、AWS、Gemini、Microsoft AutoGen 和crewAI 等系统的代理正在改变技术。
拥抱这些技术将使我们能够塑造一个人工智能使用“手和大脑”的未来,成为我们日常工作中的有用伙伴。
