



在征服了语言之后,生成人工智能着眼于征服人类固有的新领域:情感。
然而,在这种情况下,这不仅仅是为了创造一个更“人性化”的人工智能来创造产品,也是为了揭穿数十年来塑造我们对情感理解的当前理论和框架。
基于数十年的研究,我们终于准备通过语义空间理论(SST)来实现这一目标。
因此,这并不是另一个 GenAI 系列产品,而是对现状的挑战,因为它的原理也被应用于其他令人兴奋的领域,以发现新的气味等。
归纳痴迷
在过去的几十年里,两大理论塑造了对情感的理解:“基本六种”和维度模型。
极度简化?
传统上,情绪可以通过多种方法进行分类,但主要有两种。
- 基本情绪理论:
由保罗·埃克曼(Paul Ekman)带头,基本情感的概念植根于某些情感是基本的思想,确定了跨文化普遍认可的六种基本情感:快乐、悲伤、恐惧、厌恶、愤怒和惊讶。
2.尺寸模型:
另一方面,维度模型在连续的尺度或维度上对情绪进行分类,而不是离散的类别。
常见的维度模型涉及两个主要维度:效价(愉快-不愉快)和唤醒度(激活-失活)。通俗地说,效价表示情绪的积极与否,以及激发情绪的强度。
例如,幸福的效价较高(愉快),并且唤醒程度不同,而悲伤的效价较低(不愉快),并且唤醒程度也不同。
其他流行的理论包括普拉奇克情绪之轮,该理论声称我们有多达34,000 种情绪,其中一些理论已经证明了概述文化差异的至关重要性。
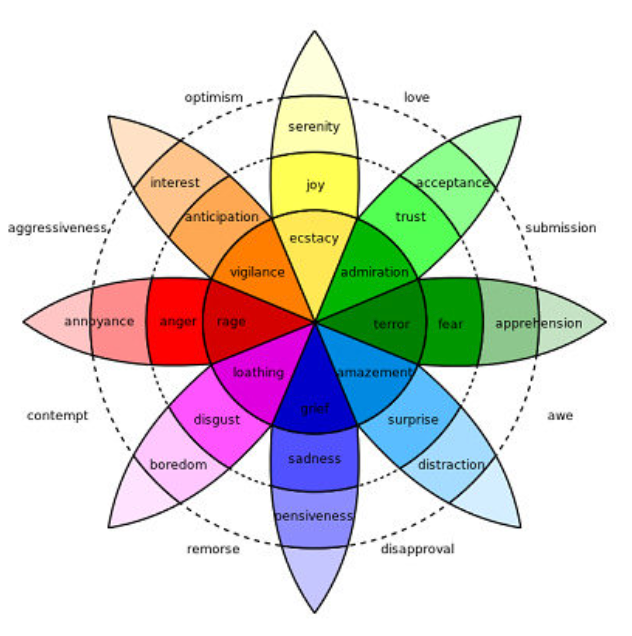
普拉奇克的情绪之轮。来源
但相当长一段时间以来,一些研究人员对这些理论提出了质疑。
走向极端经验主义
其中最引人注目的可能是加州大学伯克利分校 Dacher Keltner 等人 2017 年的一项研究,该研究将情绪数量定为27 种。
Alan Cowen 等人于 2020 年在《自然》杂志上发表的另一篇热门研究论文发现,全球范围内有 16 种面部表情出现在相似的环境中,这有助于弥合文化之间的差距。
但这两篇研究论文有什么共同点呢?
嗯,与之前混合演绎(偏离多种假设,例如所有人类情感都可以追溯到六种情感)和归纳(根据数据衡量这些假设)的理论不同,一种新型理论,称为语义空间理论( SST),采取不同的立场。
利用人工智能提供的规模力量,他们采用了纯粹的归纳方法。换句话说,不做任何假设,让数据来说话。
站在大卫·休谟或查尔斯·达尔文等巨人的肩膀上,他们认为情感分类法是由远远超过标准的六种类型(分别为 16 种和 20 种类型)组成的,一些公司的使命是让数据说话,并开始展示其中一些理论一个多世纪以来仍未得到证实。
然而,直到今天,其他更流行的理论,特别是“基本六”和效价/唤醒维度方法,仍然非常具有粘性并被广泛接受。
但人工智能可能会改变这一点。
情感的语义空间
免责声明:语义空间理论背后的研究人员 Dacher Keltner 和 Alan Cowen 是 Hume 的首席科学顾问兼首席执行官,Hume 是一家拥有生成式人工智能产品的营利性公司。
让我澄清一下,我不隶属于休谟,也没有投资休谟(不要指望本文中有任何附属链接或推荐)。
另外,请注意,其他公司(例如Meta或ElevenLabs)可能会提供类似且有竞争力的产品,您在决定什么最适合您时也应该进行基准测试。
尽管我们每天都在人工智能行业目睹极端的破坏,但很高兴看到大多数创新可以追溯到相同的原则。
向机器传授意义
其中之一是语义相似性,我认为这是当今人工智能中最重要的原则,因为这个想法不仅支持 SST 背后的研究,而且支持大多数前沿模型,如 ChatGPT、Gemini、Stable Diffusion 或 Sora。一切,无差别,都是基于这个想法。
这种情况的关键区别在于,虽然 ChatGPT 没有教我们任何有关语言的知识,但 SST 正在教人类新的情感。
但为什么?
语义相似性的整个想法源于一个关键问题:我们如何向机器传授我们的世界?
如果我们追溯这个想法的起源,我们就会得到word2vec,这是 Google 于 2014 年发表的一篇开创性研究论文。
如果我说,如果没有这篇论文,除非有人取得类似的突破,否则我们今天所看到的一切都不会发生,我一点也不夸张。
Word2Vec 的贡献可以通过“国王 – 男人 + 女人 = 女王”得到最好的理解,我们能够将单词转换为带有底层单词语义的数字向量,以至于你可以用它们进行算术运算。
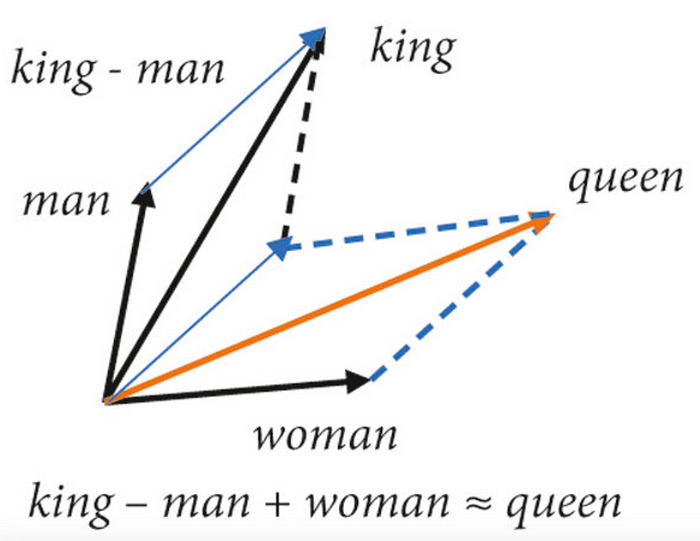
但我们到底为什么要这样做呢?
好吧,有两个原因:
- 必要性:机器只处理数字,因此我们需要找到一种方法将我们的世界变成数字形式。
- 将语义转化为数学:通过进行这种转化,我们可以将教授事物语义相似性的过程转化为数学计算。
如果你仔细想想,这和人类看待世界的方式并没有什么不同。例如,我们知道“狗”和“猫”是相似的动物,因为它们有共同的属性:四足、哺乳动物、家养等。
因此,为了教会人工智能模型以相似的方式看待世界,我们只需要确保它们的向量(称为嵌入)也相似。
这让我们想到了语义空间的概念,您可能已经看到这个概念被称为潜在空间。
这些空间有一个原则:相似的事物具有相似的向量,因此在该空间中靠近,不同的概念被推开。
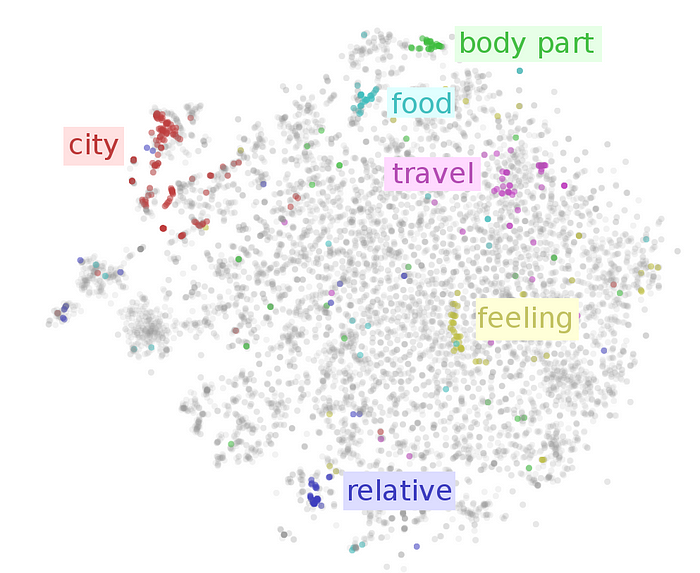
尽管你可能还不太清楚,但这种想法在当今的人工智能中无处不在,原因只有一个:
注意力。
关注就是你所需要的
基于另一篇开创性的研究论文,并因创建 Transformer 的论文而普及,注意力机制已成为序列处理的黄金标准,无论是创建文本的单词序列,还是创建图像的像素序列。
我不会详细介绍,但其想法是,每个语义信息单元,即命名的标记(例如,文本的单词,或图像的像素组)都使用注意力来根据周围的上下文更新其含义。
例如,在句子“我走到河岸”中,为了避免将“银行”与金融机构混淆,“银行”令牌将“注意”“河”以意识到它是“河岸”。
因此,尽管法学硕士本身并没有完全实现这个语义空间,但ChatGPT 明确地通过计算概念之间的相似性来处理语言。
正如前面提到的,同样的原理也适用于图像,因为在这种情况下,注意力机制也惊人地相似。
但这一切是如何引导我们进入本文的主题——语义空间理论的呢?
情感就是你所需要的一切
这个想法非常简单:一些研究人员正在尝试在高维语义空间中对情绪进行分类和区分。
换句话说,就像 ChatGPT 可能构建英语语言的语义空间(“狗”和“猫”聚集在一起且远离“椅子”的地方)一样,我们可以将相同的原则应用于情感。
如下所示,我们可以将语音韵律分为不同的类别,例如“尴尬”或“混乱”。

语音韵律语义空间。资料来源:休谟
但休姆公司远远超出了这一范围,将这一原理应用于其他概念,如声音或面部表情,或动态面部反应。
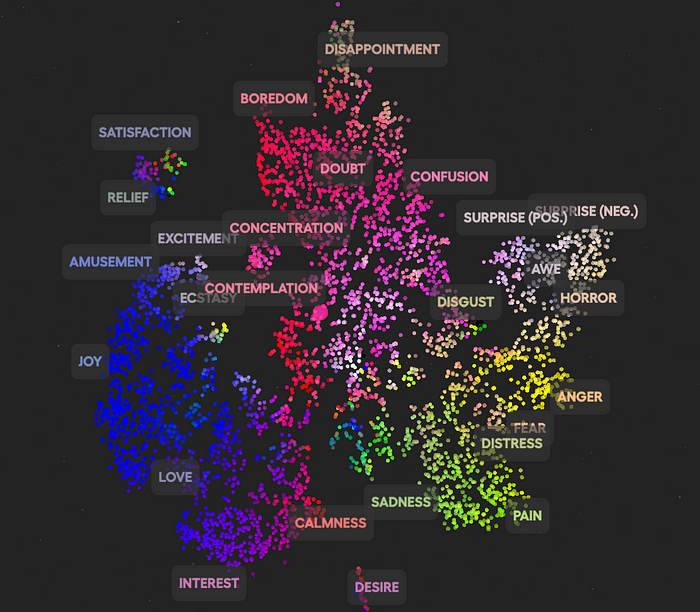
面部表情。资料来源:休谟

资料来源:休谟
更重要的是,我们可以将这些应用到其他模式中。例如,Osmo公司正在构建一个气味语义空间,使我们能够预测事物的气味,甚至创造新的气味。
但正如我一开始提到的,这个概念不仅帮助我们教会机器更好地辨别用户情绪,实际上恰恰相反,人工智能正在帮助我们确认,情绪确实比我们最初想象的要多样化得多。
人工智能作为发现工具
利用语义空间,我们正在使用数据驱动的方法来证明远远超出我们当前理解的新情感理论。
然而,我们还处于发现之路的早期阶段,因为我们应该期望这些空间的维度会增长(增加向量大小)以获得更多的粒度。
特别是,我希望您从阅读本文中了解到,我对休谟语义空间理论的深入研究只是达到目的的一种手段,目的是传达这样的想法:语义空间是当今人工智能难题的关键部分,并且除了情感之外,还可以应用于许多其他形式,例如前面提到的Osmo。
在更具体的层面上,通过利用更细粒度和更准确的语义空间,我们应该期望生成式人工智能产品在接下来的几个月和几年里变得更加“人性化”——而不是字面上的“人性化”。
但对我来说,这篇文章的主要收获是人工智能将变得多么重要,它不仅仅是一个生成器,一个发现的工具。
- 通过声音发现疾病: 研究表明,利用人工智能评估声音可以帮助发现帕金森病或冠状动脉疾病等疾病
- 谎言检测,通过揭示语音韵律中复杂的模式,如节奏或语气,来发现某人何时撒谎(休谟正在对此进行测试)。
- 更具同理心的人工智能伴侣,人工智能系统可以根据我们的声音甚至文本捕捉我们的情绪,同时不会像Inflection那样在此过程中损失数十亿美元。
还有很多。但与任何人工智能突破一样,我们还必须牢记此类系统的伦理考虑。
我们不要忘记风险
“更强大”的人工智能系统可用于:
- 通过生成更准确的深度赝品来欺骗他人,
- 通过更有针对性和更具吸引力的广告来操纵客户,
- 通过优化其输出来引发用户的负面情绪来进行心理战,
- 或者甚至可以用于生物识别应用或社会评分系统(这两种系统都已被欧盟人工智能法案禁止),但在中国等国家相当普遍。
尽管如此,此类系统的激增是不可避免的,这为人工智能提出了当今的重大问题:我们如何平衡好结果和坏结果?
