



什么是无监督学习?
无监督学习是一种机器学习(机器语言(Machine Language))使用人工智能的技术(AI)识别数据集中既未分类也未标记的模式的算法。
无监督学习模型在训练数据集时不需要监督,这使它成为发现模式、分组和差异的理想ML技术非结构化数据。它非常适合以下流程客户细分探索性数据分析或图像识别。
无监督学习算法可以对数据集中包含的数据点进行分类、标记和分组,而不需要任何外部指导来执行该任务。换句话说,无监督学习允许系统识别数据集中的模式就其本身而言。
在无监督学习中,即使没有提供类别,AI系统也会根据相似性和差异对未排序的信息进行分组。
能够进行无监督学习的AI系统通常与生成学习模型相关联,尽管它们也可能使用基于检索的方法,这通常与监督学习相关联。聊天机器人,自动驾驶汽车,面部识别程序,专家系统机器人属于使用监督或无监督学习方法的系统。无监督学习也称为无监督机器学习.
无监督学习如何工作
无监督学习始于机器学习工程师或数据科学家通过算法传递数据集来训练它们。在用于训练这种系统的数据集中不包含标签或类别;在训练期间通过算法传递的每条数据都是一个未标记的输入对象或样本。
无监督学习的目标是让算法识别训练数据集中的模式,并根据系统本身识别的模式对输入对象进行分类。这些算法通过从数据集中提取有用的信息或特征来分析数据集的底层结构。因此,期望这些算法通过寻找每个样本或输入对象之间的关系来开发特定的输出。
例如,无监督学习算法可能被给予包含动物图像的数据集。这些算法可以将动物分类,比如有皮毛的、有鳞片的和有羽毛的。然后,随着算法学习识别每个类别中的区别,它们将图像分组为越来越具体的子组。
算法通过发现和识别模式来做到这一点。在无监督学习中,模式识别在没有向系统输入数据来教它区分特定类别的情况下发生。
无监督与监督学习和半监督学习
监督学习是一种类似于非监督学习的ML技术,但在监督学习中,数据科学家向算法提供带标签的训练数据,并定义他们希望算法评估的变量。
与无监督学习不同,算法的输入数据和输出变量都在训练数据中指定。以动物为例,数据科学家将为算法提供每种动物的照片,并为训练数据中使用的每张照片创建一个标签,以表明图像中是否包含动物以及它属于哪个类别。
训练监督学习模型,直到它们能够检测输入数据和输出标签之间的模式和关系。分类、决策树、回归和预测建模是监督算法的常见类型。
监督学习与非监督学习的比较监督学习使用带标签的数据集来训练算法,以根据提供的标签进行识别和分类。无监督学习比监督学习模型更不可预测。例如,虽然无监督学习的人工智能系统可能会自己找出如何将猫和狗分类,但它也可能会添加无法预见和不希望的类别来处理不寻常的品种,从而造成混乱而不是有序。
ML工程师或数据科学家可以选择使用标记和未标记数据的组合来训练他们的算法。这种介于两者之间的选择被恰当地称为半监督学习.
在半监督机器学习中,通过标记和未标记数据的混合来教授算法。这个过程从一组人类建议和类别开始,然后使用无监督学习来帮助通知监督学习过程。半监督学习提供了定义数据标签的自由,同时仍然受到人类视角的指导。
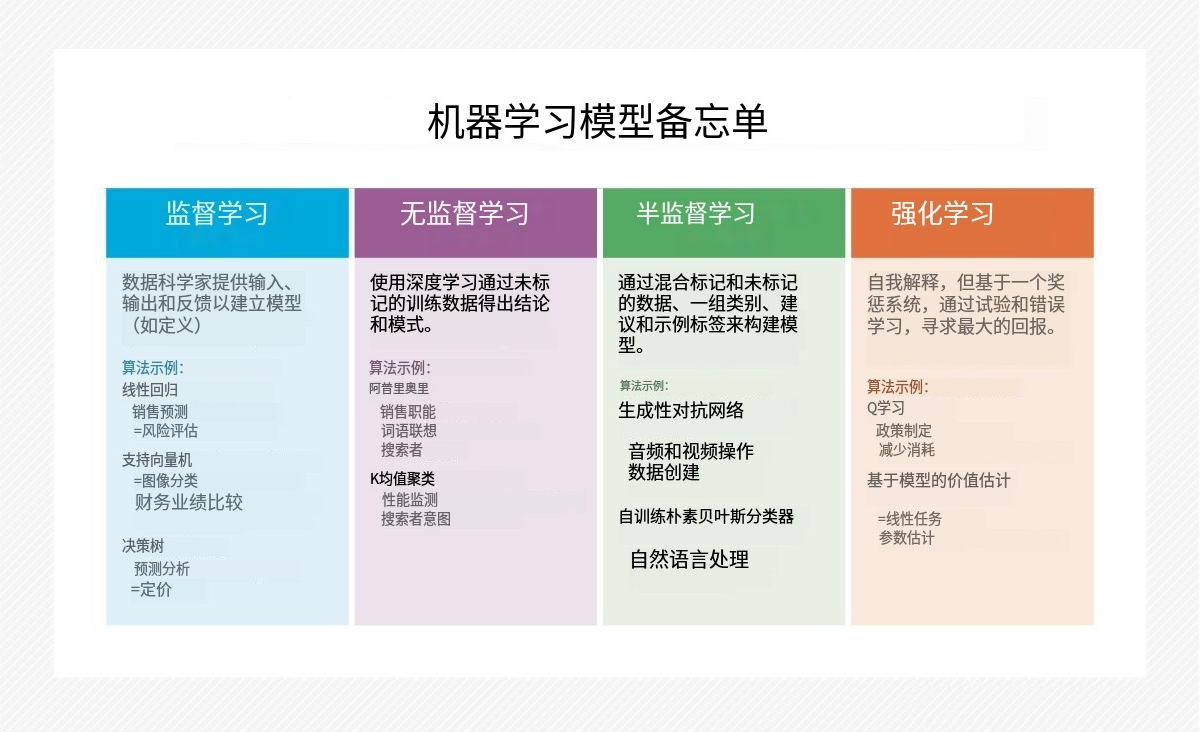
另一种机器学习技术是强化学习这是基于奖励想要的行为和惩罚不想要的行为。在这个过程中,开发人员创建了一种方法,将正值分配给期望的行为,将负值分配给不期望的行为。
聚类和其他类型的无监督学习
无监督学习通常侧重于聚类。聚类是将相似的对象或数据点分组,同时将不相似的对象放在其他聚类中。
机器学习工程师和数据科学家可以使用不同的算法进行聚类,算法本身根据其工作方式分为不同的类别。聚类算法可以分为以下几类:
- 独占聚类。这种数据分组形式指定一个数据点只能存在于一个簇中。
- 重叠聚类。这种形式的数据分组使数据点能够属于多个具有不同成员级别的聚类。
- 分层聚类。这种形式的分组数据分为聚集型和分裂型。聚集聚类最初将数据点设置为单独的分组,随后进行合并,而分裂聚类采用单个数据聚类并根据数据点对其进行划分。
- 概率聚类。这种形式的数据点分组是基于它们属于特定分布的可能性。高斯混合模型通常用于表示总体中的子群体。
一些更广泛使用的算法包括k均值聚类算法、模糊k-均值算法、层次聚类和基于密度的聚类算法。
无监督学习的好处
无监督学习的好处包括:
- 处理复杂的任务。无监督学习比监督学习更有用,监督学习的初始输入数据更复杂和无结构。
- 不需要解读标签。ML工程师和数据科学家负责通过算法传递数据集来训练它们,但他们不需要解释每个数据点的标签。
- 从原始数据集中获得意义。与人相比,人工智能工具可以更快地评估原始数据。
- 识别非结构化数据集中的潜在模式。无监督学习可用于识别大量不同数据点之间的共同因素。
- 实时工作。无监督学习可以利用实时数据来识别模式。
- 比监督学习成本低。无监督学习不需要监督学习所需的与标注数据相关联的手动工作。
无监督学习的挑战
尽管组织重视无监督学习的有益特性,但也有一些缺点,包括以下几点:
- 结果可能无法预测。很难检查无监督学习输出的准确性,因为没有标记的数据集来验证结果。
- 更长的整体训练时间。无监督学习模型需要大量的训练集来产生结果,并且从原始数据中学习可能非常耗时。
- 缺乏洞察力。识别大型未分类数据集中的隐藏模式会使训练过程更加困难。
聚类还有一个额外的缺点,即聚类分析可能会高估输入对象的相似性。这可能会掩盖对某些用例很重要的单个数据点,例如客户细分,其目标是了解单个客户及其独特的购买习惯。
示例和使用案例
探索性分析和降维是无监督学习的两个最常见的用途。
探索性分析使用算法来检测以前未知的模式,具有广泛的企业应用。举个例子,企业可以使用探索性分析作为客户细分工作的起点。
在降维中,算法减少了数据集中的变量或特征(维度)的数量,以便关注各种目标的相关特征。一些专家解释说,降维去除了噪声数据。机器学习工程师经常使用基于潜在变量模型的算法来完成这项工作。例如,组织可以通过减少背景来使用降维来读取模糊的图像。
此外,组织可以将无监督学习用于以下应用:
- 聚类异常检测 这种技术使用无监督学习来检测数据集分组中异常值的性能,而无需标记数据。
- 关联规则挖掘 无监督学习识别大型数据集中的出现模式以及它们如何相互影响。该应用程序通常用于检测可疑活动、疾病症状和客户购物习惯。
- 网络安全 网络安全在无监督学习中训练的软件可以帮助检测网络攻击可能发生的时间以及地点和方式。
- 客户细分 营销团队根据客户的类别个性化他们的广告策略。
- 医学成像 医疗保健组织使用放射学和病理学设备中的无监督机器学习功能来帮助检测和诊断患者。
- 预后有效性 通常用于医疗保健,该应用程序将具有相似健康问题的患者分组,并预测这些患者的长期表现。
- 推荐引擎 组织收集有关人们浏览、购物和观看习惯的数据,为他们提供个性化内容。
