



什么是机器学习?
机器学习(ML)是一种人工智能(人工智能)允许软件应用程序在预测结果时变得更加准确,而无需显式编程来这样做。机器学习算法使用历史数据作为输入来预测新的输出值。
推荐引擎是机器学习的常见用例。其他流行的应用包括欺诈检测、垃圾邮件过滤、恶意软件威胁检测,业务流程自动化(BPA)和预测性维护。
为什么机器学习很重要?
机器学习很重要,因为它让企业了解客户行为和业务运营模式的趋势,并支持新产品的开发。许多当今的领先公司,如脸书、谷歌和优步,都将机器学习作为其运营的核心部分。机器学习已经成为许多公司的重要竞争优势。
机器学习有哪些不同的类型?
经典机器学习通常按照算法如何学习变得更加准确来分类。有四种基本方法:监督学习,无人监督的学习、半监督学习和强化学习。科学家选择使用的算法数据类型取决于他们想要预测的数据类型。
- 监督学习:在这种机器学习中,数据科学家为算法提供带标签的训练数据,并定义它们希望算法评估相关性的变量。算法的输入和输出都是指定的。
- 无监督学习:这种类型的机器学习涉及对未标记数据进行训练的算法。该算法扫描数据集,寻找任何有意义的联系。算法训练的数据以及它们输出的预测或建议都是预先确定的。
- 半监督学习:这种机器学习的方法包括前面两种类型的混合。数据科学家可能会输入一个算法培训用数据,但是模型可以自由地探索自己的数据,并发展自己对数据集的理解。
- 强化学习:数据科学家通常使用强化学习教机器完成有明确规则的多步骤过程。数据科学家编写算法来完成一项任务,并在它计算出如何完成一项任务时给它积极或消极的提示。但在很大程度上,算法自己决定在这个过程中采取什么步骤。
有监督的机器学习是如何工作的?
监督机器学习需要数据科学家用标记的输入和期望的输出来训练算法。监督学习算法适用于以下任务:
- 二元分类:将数据分为两类。
- 多类分类:在两种以上的答案中选择。
- 回归建模:预测连续值。
- 组装:组合多个机器学习模型的预测以产生准确的预测。
无监督机器学习是如何工作的?
无监督的机器学习算法不需要对数据进行标记。他们筛选未标记的数据,寻找可用于将数据点分组为子集的模式。大多数类型的深度学习,包括神经网络,都是无监督的算法。无监督学习算法适用于以下任务:
- 聚类:基于相似性将数据集分成组。
- 异常检测:识别数据集中的异常数据点。
- 关联挖掘:识别数据集中经常一起出现的几组项目。
- 降维:减少数据集中变量的数量。
半监督学习是如何工作的?
半监督学习的工作原理是由数据科学家提供少量的标记的训练数据一个算法。由此,算法学习数据集的维度,然后可以应用于新的、未标记的数据。当算法在标记数据集上训练时,它们的性能通常会提高。但是标注数据既费时又费钱。半监督学习在监督学习的性能和非监督学习的效率之间找到了一个中间点。使用半监督学习的一些领域包括:
- 机器翻译:教算法翻译语言的基础不是一个完整的字典。
- 欺诈检测:当你只有几个正面的例子时,识别欺诈案例。
- 标签数据:在小数据集上训练的算法可以学习应用数据标签自动转换到更大的集合。
强化学习是如何工作的?
强化学习的工作原理是编程一个算法有一个明确的目标和实现该目标的一套规定的规则。数据科学家还对算法进行编程,以寻求积极的奖励——当它执行有利于最终目标的行动时,它会收到积极的奖励——并避免惩罚——当它执行使其远离最终目标的行动时,它会收到惩罚。强化学习常用于以下领域:
- 机器人技术:机器人可以利用这项技术学习在现实世界中执行任务。
- 视频游戏:强化学习已经被用来教机器人玩一些视频游戏。
- 资源管理:给定有限的资源和明确的目标,强化学习可以帮助企业计划如何分配资源。
机器学习是如何工作的
谁在使用机器学习,它是用来做什么的?
今天,机器学习被广泛应用。也许机器学习最著名的例子之一就是推荐引擎这为脸书的新闻提供了动力。
脸书使用机器学习来个性化每个成员的供稿方式。如果某个成员经常停下来阅读某个特定群组的帖子,推荐引擎就会在feed中更早地显示该群组的更多活动。
在幕后,引擎试图强化成员在线行为中的已知模式。如果该成员改变了模式,在接下来的几周内没有阅读该组的帖子,新闻提要将相应地进行调整。
除了推荐引擎,机器学习的其他用途包括:
- 客户关系管理 CRM软件可以使用机器学习模型来分析电子邮件,并提示销售团队成员首先回复最重要的邮件。更先进的系统甚至可以推荐潜在的有效响应。
- 商业智能 商业智能和分析供应商在其软件中使用机器学习来识别潜在的重要数据点、数据点模式和异常。
- 人力资源信息系统 HRIS系统公司可以使用机器学习模型来筛选申请,并确定空缺职位的最佳候选人。
- 自动驾驶汽车 机器学习算法甚至可以让半自动汽车以识别部分可见的物体并提醒驾驶员。
- 虚拟助理 智能助手通常结合有监督和无监督的机器学习模型来解释自然语音并提供上下文。
机器学习的优缺点是什么?
机器学习已经看到了从预测客户行为到形成自动驾驶汽车操作系统的各种用例。
说到优势,机器学习可以帮助企业更深层次地了解客户。通过收集客户数据并将其与一段时间内的行为相关联,机器学习算法可以学习关联,并帮助团队根据客户需求定制产品开发和营销计划。
一些公司将机器学习作为其商业模式的主要驱动力。例如,优步使用算法来匹配司机和乘客。谷歌使用机器学习在搜索中显示乘车广告。
但是机器学习也有缺点。首先也是最重要的,它可能很贵。机器学习项目通常由数据科学家推动,他们拿着高薪。这些项目还需要昂贵的软件基础设施。
还有机器学习偏差的问题。在排除某些人群或包含错误的数据集上训练的算法可能导致不准确的世界模型,往好里说是失败,往坏里说是歧视。当企业将核心业务流程建立在有偏见的模型上时,它可能会遭遇监管和声誉损害。
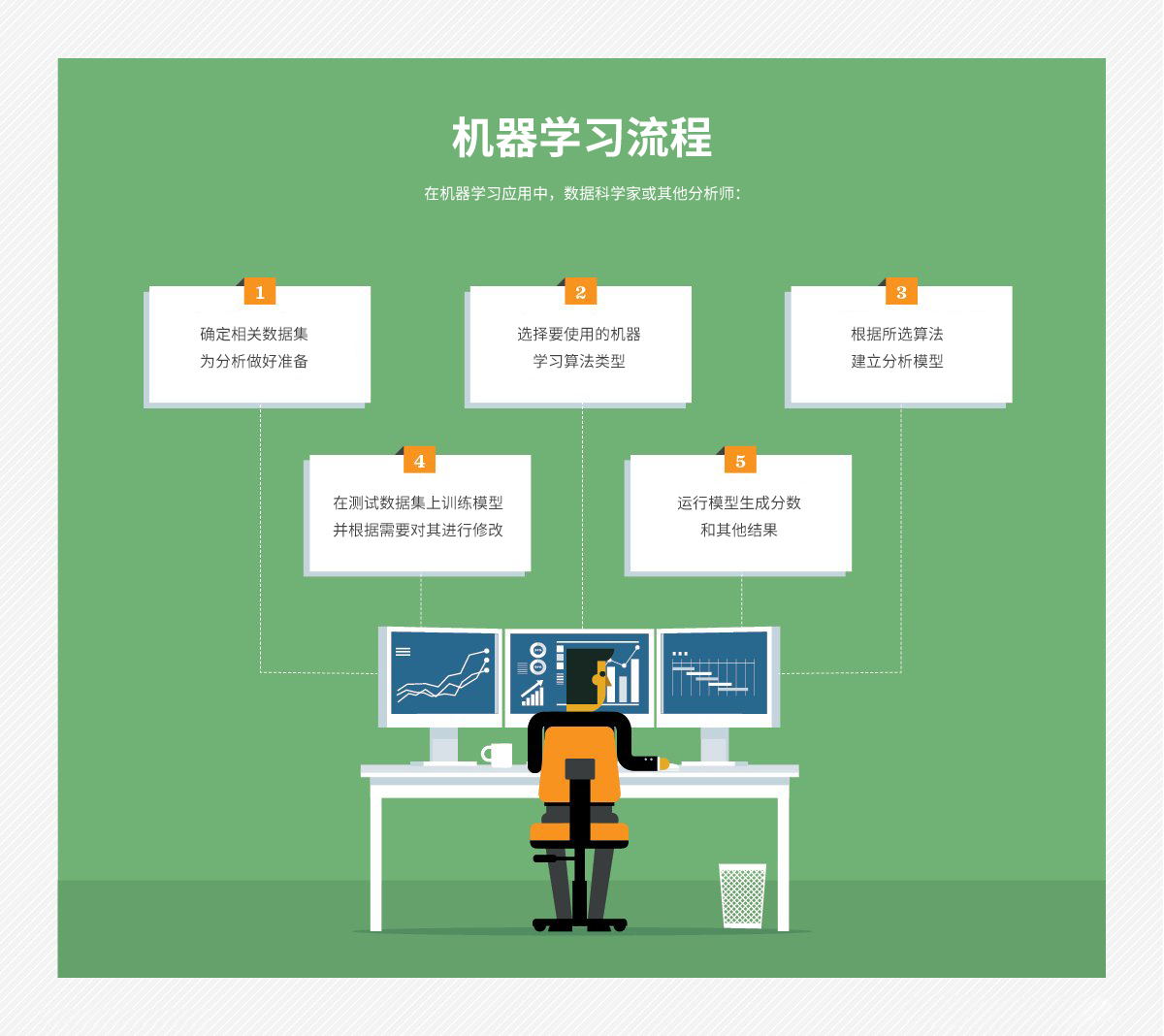
如何选择合适的机器学习模型
如果没有战略性地处理,选择正确的机器学习模型来解决问题的过程可能会很耗时。
第一步:将问题与解决方案中应考虑的潜在数据输入联系起来。这一步需要对问题有深刻理解的数据科学家和专家的帮助。
第二步:收集数据,将其格式化,并在必要时标记数据。这一步通常由数据科学家在数据辩论者的帮助下领导。
第三步:选择要使用的算法,并测试它们的性能。这一步通常由数据科学家来完成。
第四步:继续微调输出,直到达到可接受的精度水平。这一步通常由数据科学家在对问题有深刻理解的专家的反馈下进行。
人类可解释的机器学习的重要性
当模型很复杂时,解释一个特定的ML模型是如何工作的是一个挑战。在一些垂直行业中,数据科学家必须使用简单的机器学习模型,因为解释每个决策是如何做出的对于业务来说很重要。这在重工业中尤其如此合规负担比如银行和保险。
复杂的模型可以产生准确的预测,但是向外行人解释产量是如何确定的可能是困难的。
机器学习的未来是怎样的?
虽然机器学习算法已经存在了几十年,但它们获得了新的流行,因为人工智能变得越来越突出。特别是深度学习模型,为当今最先进的人工智能应用提供了动力。
机器学习平台是企业技术中竞争最激烈的领域之一,包括亚马逊、谷歌、微软、IBM等在内的大多数主要供应商都在竞相为客户注册平台服务,这些服务涵盖了机器学习活动的各个领域,包括数据收集、数据准备、数据分类、模型构建、培训和应用部署。
随着机器学习对商业运营的重要性不断增加,人工智能在企业环境中变得更加实用,机器学习平台战争只会加剧。
对深度学习和人工智能的持续研究越来越专注于开发更通用的应用程序。今天的人工智能模型需要大量的训练,才能产生高度优化的算法来执行一项任务。但一些研究人员正在探索使模型更加灵活的方法,并寻求允许机器将从一项任务中学习到的上下文应用到未来不同任务的技术。

机器学习是如何进化的?
1642年的今天,布莱士·帕斯卡发明了一种可以加减乘除的机械。
1679年的今天,戈特弗里德·威廉·莱布尼茨设计了二进制的代码。
1834年的今天,查尔斯·巴贝奇构思出一种可以用穿孔卡片编程的通用装置。
1842 – 阿达·洛芙莱斯描述了使用查尔斯·巴贝奇理论解决数学问题的一系列操作穿孔卡片机成为第一个程序员。
1847年的今天,乔治·布尔创造了布尔代数学体系的逻辑,代数的一种形式,其中所有值都可以简化为真或假的二进制值。
1936年-英国逻辑学家和密码分析师艾伦·图灵提出了一种可以破译和执行一组指令的通用机器。他发表的证明被认为是计算机科学的基础。
1952年的今天,亚瑟·塞缪尔创造了一个程序来帮助一台IBM电脑更好地玩跳棋。
1959年的今天,马达琳成为第一个人工神经网络应用于一个现实世界的问题:消除电话线的回声。
1985年,特里·塞伊诺夫斯基和查尔斯·罗森伯格的人工神经网络在一周内自学了如何正确发音20000个单词。
1997年的今天,IBM的“深蓝”击败了国际象棋特级大师加里·卡斯帕罗夫。
1999年A计算机辅助设计原型智能工作站审查了22,000张乳房x光照片,比放射科医生更准确地检测出52%的癌症。
2006年的今天,计算机科学家杰弗里·辛顿发明了这个术语深度学习来描述神经网络研究。
2012年——由谷歌创建的一个无监督神经网络学会了识别YouTube视频中的猫,准确率达到74.8%。
2014年AI聊天机器人通过说服33%的人类法官相信是一个名叫尤金·古斯特曼的乌克兰少年,从而通过图灵测试。
2014年的今天,谷歌的AlphaGo在世界上最难的棋盘游戏围棋中击败了人类冠军。
2016年——deep mind的人工智能系统LipNet识别视频中的唇读单词,准确率达到93.4%。
2019年-亚马逊控制了70%的市场份额虚拟助手在美国。

